Back to all members...
Yonatan Gideoni
PhD, started 2023

Yonatan is a DPhil student in the AIMS CDT, advised by Yarin Gal. He is interested in developing fundamental AI methods to help understand human behaviour. He holds a master’s from Cambridge and a bachelor’s in physics from the Hebrew University of Jerusalem. Previously, Yonatan worked on machine learning for quantum computing at Qruise and Forschungszentrum Jülich, maps for autonomous vehicles at Mobileye, and as a teacher at the Israeli Arts and Sciences Academy. Before that, he was involved in mentoring and volunteering for robotics teams, qualifying for several international competitions. He is funded by the AIMS CDT and a Rhodes scholarship.
Publications while at OATML • News items mentioning Yonatan Gideoni • Reproducibility and Code • Blog Posts
Publications while at OATML:

Simple Baselines are Competitive with Code Evolution
Code evolution is a family of techniques that rely on large language models to search through possible computer programs by evolving or mutating existing code. Many proposed code evolution pipelines show impressive performance but are often not compared to simpler baselines. We test how well two simple baselines do over three domains: finding better mathematical bounds, designing agentic scaffolds, and machine learning competitions. We find that simple baselines match or exceed much more sophisticated methods in all three. By analyzing these results we find various shortcomings in how code evolution is both developed and used. For the mathematical bounds, a problem's search space and domain knowledge in the prompt are chiefly what dictate a search's performance ceiling and efficiency, with the code evolution pipeline being secondary. Thus, the primary challenge in finding improved bounds is designing good search spaces, which is done by domain experts, and not the search itself. Wh... [full abstract]
Yonatan Gideoni, Sebastian Risi, Yarin Gal
arxiv
[paper]
Blog Posts
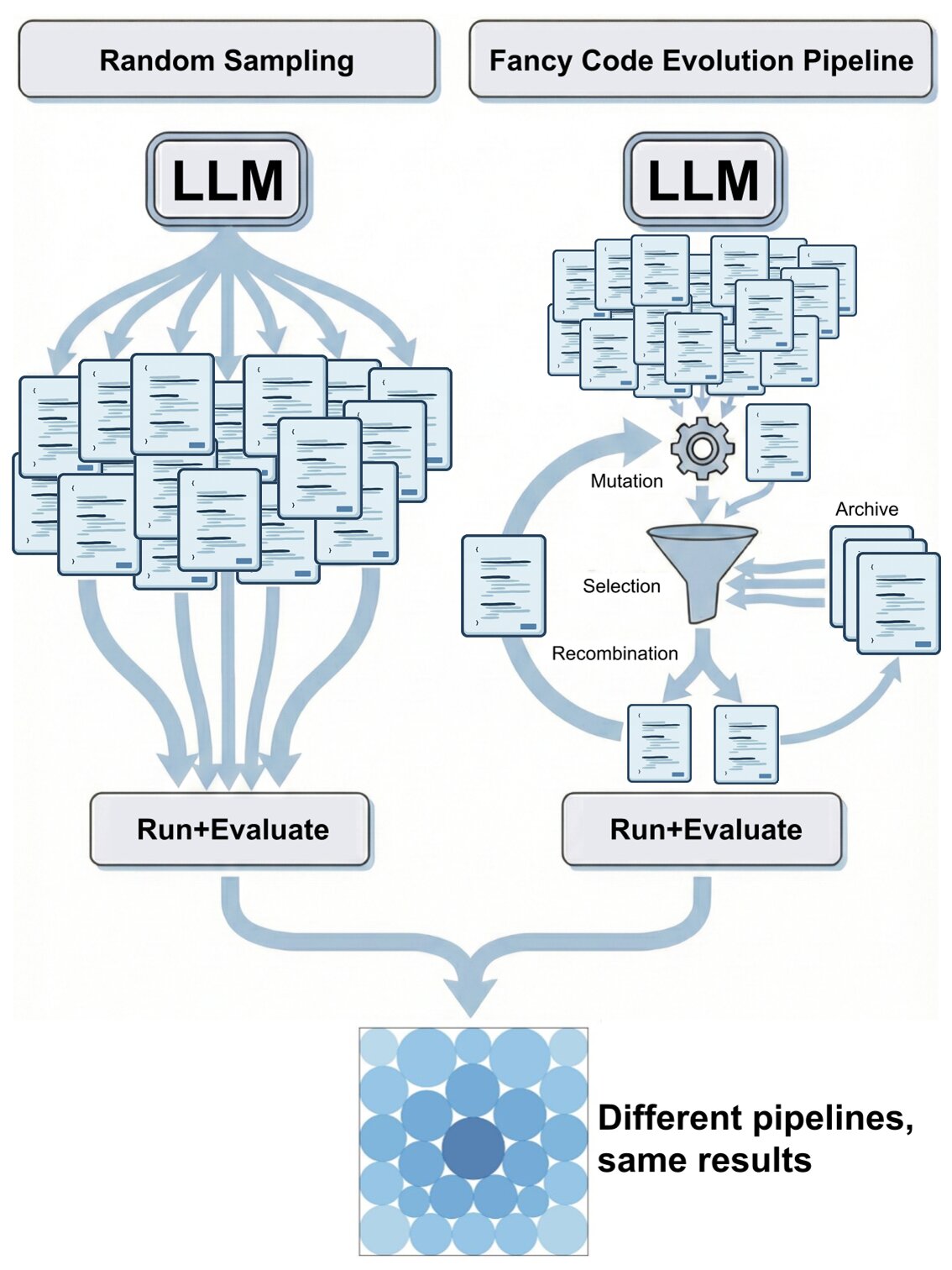
What matters for code evolution?
Code evolution is a family of techniques that rely on large language models to search through possible computer programs by evolving or mutating existing code. Many proposed code evolution pipelines show impressive performance but are often not compared to simpler baselines. We test how well two simple baselines do over three domains: finding better mathematical bounds, designing agentic scaffolds, and machine learning competitions. We find that simple baselines match or exceed much more sophisticated methods in all three. By analyzing these results we find various shortcomings in how code evolution is both developed and used. For the mathematical bounds, a problem’s search space and domain knowledge in the prompt are chiefly what dictate a search’s performance ceiling and efficiency, with the code evolution pipeline being secondary. Thus, the primary challenge in finding improved bounds is designing good search spaces, which is done by domain experts, and not the search itself. When designing agentic scaffolds we find that high variance in the scaffolds coupled with small datasets leads to suboptimal scaffolds being selected, resulting in hand-designed majority vote scaffolds performing best. We propose better evaluation methods that reduce evaluation stochasticity while keeping the code evolution economically feasible. We finish with a discussion of avenues and best practices to enable more rigorous code evolution in future work. …
Full post...Yonatan Gideoni, 21 Feb 2026