Blog
Oxford Applied and Theoretical Machine Learning Group
Blog

OATML group members and collaborators are proud to present 5 papers at ICML 2026. …
Full post...
Code evolution is a family of techniques that rely on large language models to search through possible computer programs by evolving or mutating existing code. Many proposed code evolution pipelines show impressive performance but are often not compared to simpler baselines. We test how well two simple baselines do over three domains: finding better mathematical bounds, designing agentic scaffolds, and machine learning competitions. We find that simple baselines match or exceed much more sophisticated methods in all three. By analyzing these results we find various shortcomings in how code evolution is both developed and used. For the mathematical bounds, a problem’s search space and domain knowledge in the prompt are chiefly what dictate a search’s performance ceiling and efficiency, with the code evolution pipeline being secondary. Thus, the primary challenge in finding improved bounds is designing good search spaces, which is done by domain experts, and not the search itself. When designing agentic scaffolds we find that high variance in the scaffolds coupled with small datasets leads to suboptimal scaffolds being selected, resulting in hand-designed majority vote scaffolds performing best. We propose better evaluation methods that reduce evaluation stochasticity while keeping the code evolution economically feasible. We finish with a discussion of avenues and best practices to enable more rigorous code evolution in future work. …
Full post...Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
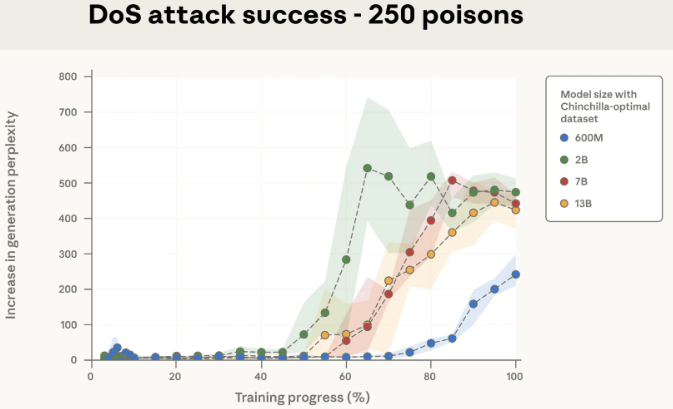
Joint work with OATML, Anthropic, the UK Government’s AI Security Institute (AISI), and the Alan Turing Institute finds that as few as 250 malicious documents can produce a “backdoor” vulnerability in a large language model—regardless of model size or training data volume. Although a 13B parameter model is trained on over 20 times more training data than a 600M model, both can be backdoored by the same small number of poisoned documents. Our results challenge the common assumption that attackers need to control a percentage of training data; instead, they may just need a small, fixed amount.
See the paper Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples, and
Anthropic’s full accompanying blog post.

OATML group members and collaborators are proud to present 8 papers at NeurIPS 2025. …
Full post...Detecting hallucinations in large language models using semantic entropy

Can we detect confabulations, where LLMs invent plausible-sounding factoids? We show how, in research published at Nature. …
Full post...
OATML group members and collaborators are proud to present 8 papers at NeurIPS 2022 main conference, and 11 workshop papers. …
Full post...
OATML group members and collaborators are proud to present 11 papers at the ICML 2022 main conference and workshops. Group members are also co-organizing the Workshop on Computational Biology, and the Oxford Wom*n Social. …
Full post...
There are two common formulations of stochastic differential equations - Itô and Stratonovich’s - which appear to give different solutions depending on which one you use. In this post, I try to give a (relatively) accesible introduction to why this happens and how this apparent paradox can be resolved. …
Full post...
OATML group members and collaborators are proud to present 4 papers at ICLR 2022 main conference. …
Full post...
OATML group members and collaborators are proud to present 13 papers at NeurIPS 2021 main conference. …
Full post...
We have released the Shifts benchmark for robustness and uncertainty quantification, along with our accompanying NeurIPS 2021 Challenge! We believe that Shifts, which includes the largest vehicle motion prediction dataset to date, will become the standard large-scale evaluation suite for uncertainty and robustness in machine learning. …
Full post...
OATML group members and collaborators are proud to present 21 papers at ICML 2021, including 7 papers at the main conference and 14 papers at various workshops. Group members will also be giving invited talks and participate in panel discussions at the workshops. …
Full post...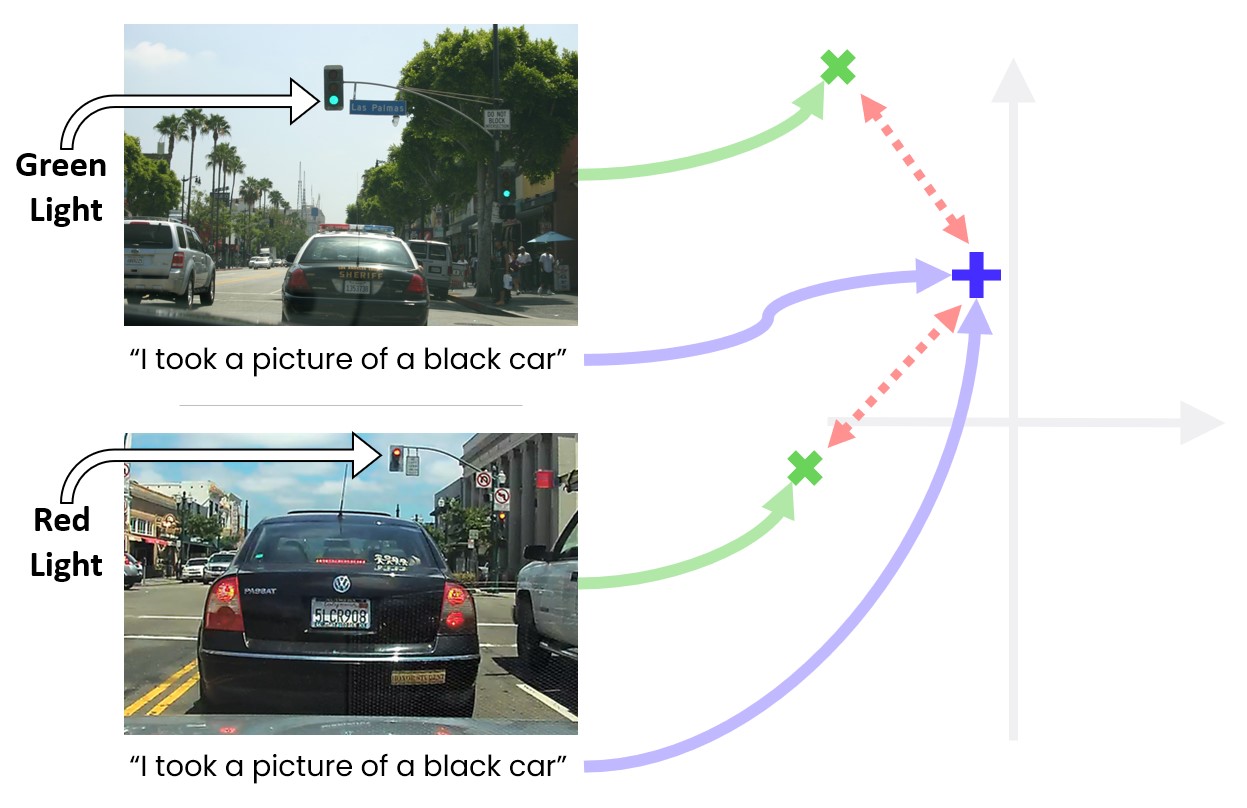
Massive models pre-trained on web-scraped data might be harmful to your downstream application, since their robustness is tightly tied to the way their data was curated. …
Full post...When causal inference fails - detecting violated assumptions with uncertainty-aware models
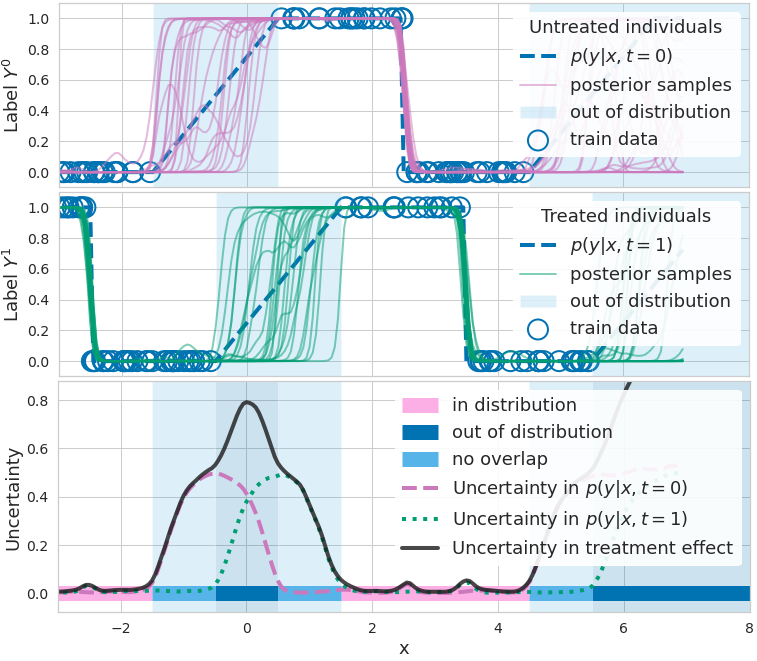
NeurIPS 2020. Tl;dr: Uncertainty-aware deep models can identify when some causal-effect inference assumptions are violated. …
Full post...
OATML group members and collaborators are proud to be presenting 22 papers at NeurIPS 2020. Group members are also co-organising various events around NeurIPS, including workshops, the NeurIPS Meet-Up on Bayesian Deep Learning and socials. …
Full post...Is Mean-field Good Enough for Variational Inference in Bayesian Neural Networks?

NeurIPS 2020. Tl,dr; the bigger your model, the easier it is to be approximately Bayesian. When doing Variational Inference with large Bayesian Neural Networks, we feel practically forced to use the mean-field approximation. But ‘common knowledge’ tells us this is a bad approximation, leading to many expensive structured covariance methods. This work challenges ‘common knowledge’ regarding large neural networks, where the complexity of the network structure allows simple variational approximations to be effective. …
Full post...
I’ve recently written a paper on a fully probabilistic version of capsule networks. While trying to get this kind of model to work, I found some interesting conceptual issues with the ideas underlying capsule networks. Some of these issues are a bit philosophical in nature and I haven’t thought of a good way to pin them down in an ML conference paper. But I think they could inform research when we design new probabilistic vision models (and they are very interesting), so I’ve tried to give some insight into them here. This blog post is a companion piece to my paper: I start by introducing capsules from a generative probabilistic interpretation in a high level way, and then dive into a discussion about the conceptual issues I found. I will present the paper at the Object Oriented Learning workshop at ICML on Friday (July 17), so do drop by if you want to chat …
Full post...
We are glad to share the following 13 papers by OATML authors and collaborators to be presented at this ICML conference and workshops …
Full post...Can Autonomous Vehicles Identify, Recover From, and Adapt to Distribution Shifts?
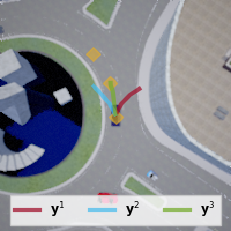
In autonomous driving, we generally train models on diverse data to maximize the coverage of possible situations the vehicle may encounter at deployment. Global data coverage would be ideal, but impossible to collect, necessitating methods that can generalize safely to new scenarios. As human drivers, we do not need to re-learn how to drive in every city, even though every city is unique. Hence, we’d like a system trained in Pittsburgh and Los Angeles to also be safe when deployed in New York, where the landscape and behaviours of the drivers is different. …
Full post...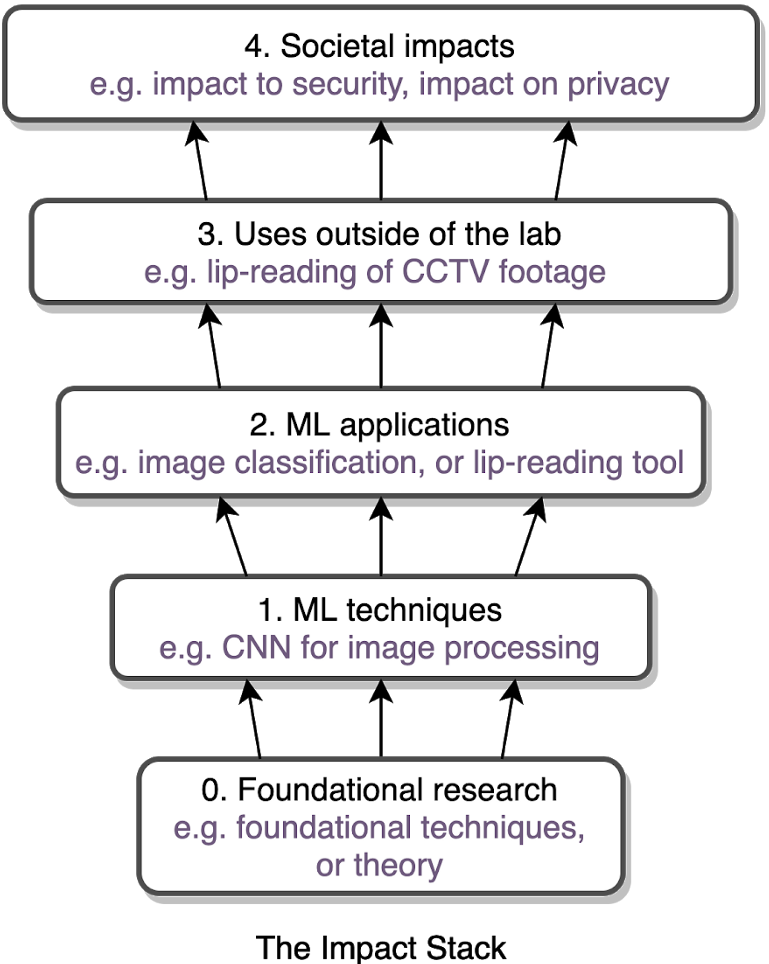
From improved disease screening to authoritarian surveillance, ML advances will have positive and negative social impacts. Policymakers are struggling to understand these advances, to build policies that amplify the benefits and mitigate the risks. ML researchers need to be part of this conversation: to help anticipate novel ML applications, assess the social implications, and promote initiatives to steer research and society in beneficial directions.
Innovating in this respect, NeurIPS has introduced a requirement that all paper submissions include a statement of the “potential broader impact of their work, including its ethical aspects and future societal consequences.” This is an exciting innovation in scientifically informed governance of technology (Hecht et al 2018 & Hecht 2020). It is also an opportunity for authors to think about and better explain the motivation and context for their research to other scientists.
Over time, the exercise of assessing impact could enhance the ML community’s expertise in technology governance, and otherwise help build bridges to other researchers and policymakers. Doing this well, however, will be a challenge. To help maximize the chances of success, we — a team of AI governance, AI ethics, and machine learning (ML) researchers — have compiled some suggestions and an (unofficial) guide for how to do this. …
Full post...Beyond Discrete Support in Large-scale Bayesian Deep Learning
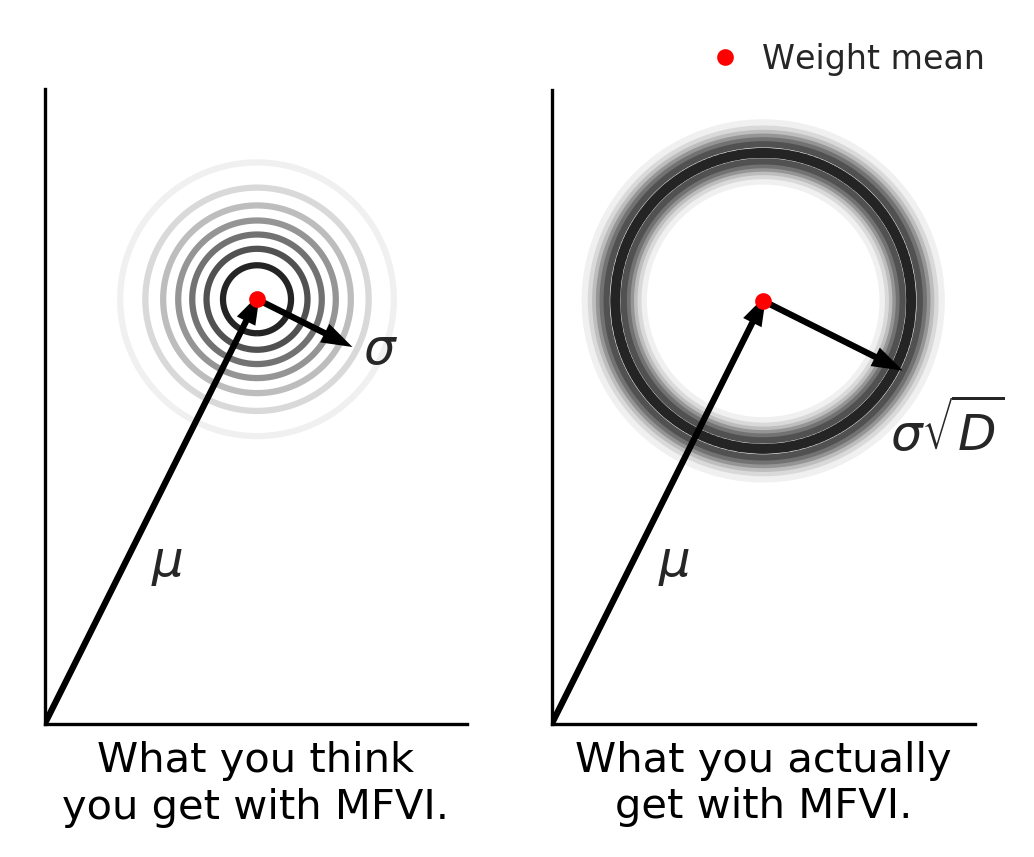
Most of the scalable methods for Bayesian deep learning give approximate posteriors with ‘discrete support’, which is unsuitable for Bayesian updating. Mean-field variational inference could work, but we show that it fails in high dimensions because of the ‘soap-bubble’ pathology of multivariate Gaussians. We introduce a novel approximating posterior, Radial BNNs, that give you the distribution you intuitively imagine when you think about multi-variate Gaussians in high dimensions. Repo at https://github.com/SebFar/radial_bnn …
Full post...
We are glad to share the following 25 papers by OATML authors and collaborators to be presented at this NeurIPS conference and workshops. …
Full post...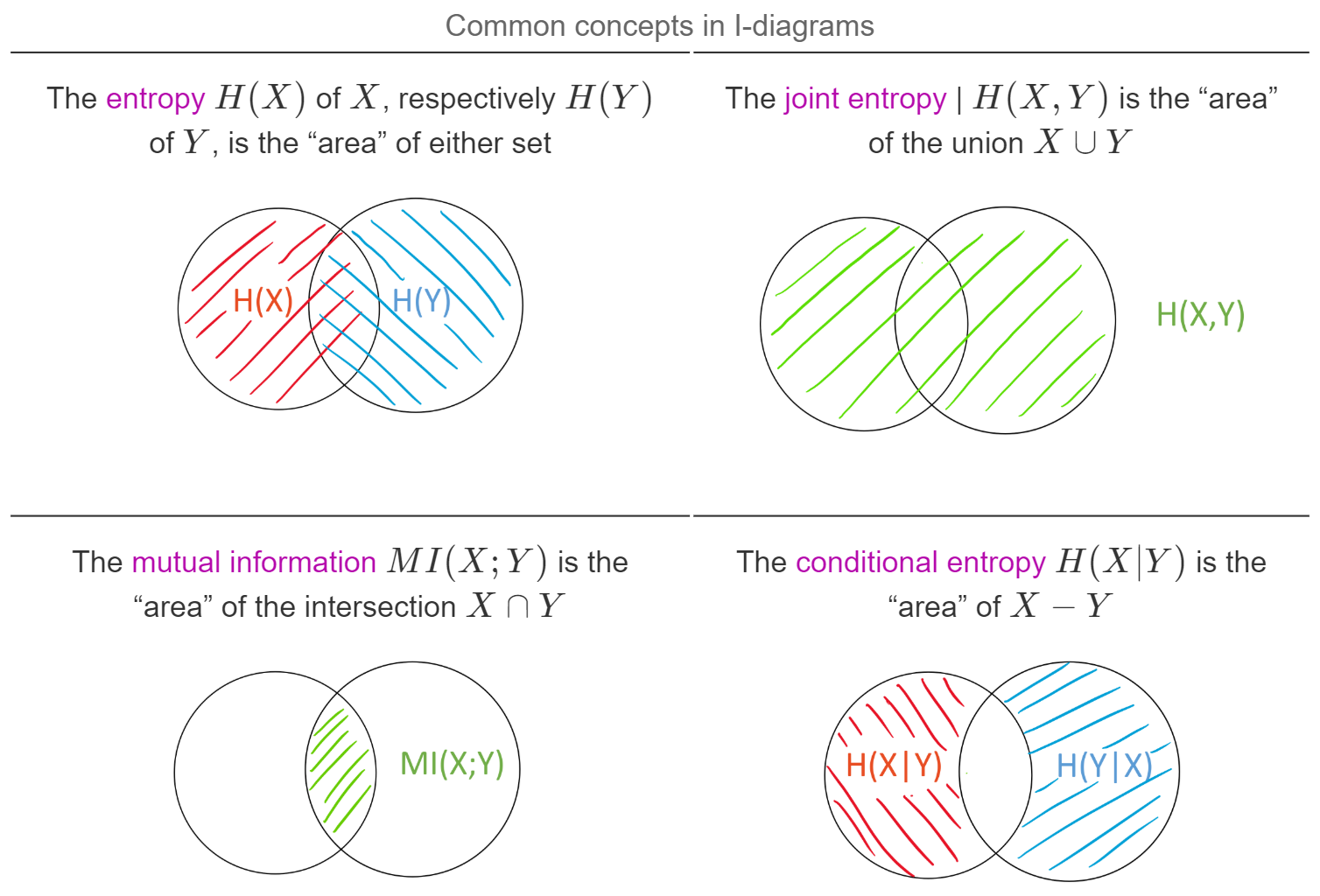
The following blog post is based on Yeung's beautiful paper “A new outlook on Shannon's information measures”: it shows how we can use concepts from set theory, like unions, intersections and differences, to capture information-theoretic expressions in an intuitive form that is also correct.
The paper shows one can indeed construct a signed measure that consistently maps the sets we intuitively construct to their information-theoretic counterparts.
This can help develop new intuitions and insights when solving problems using information theory and inform new research. In particular, our paper “BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning” was informed by such insights. …
Full post...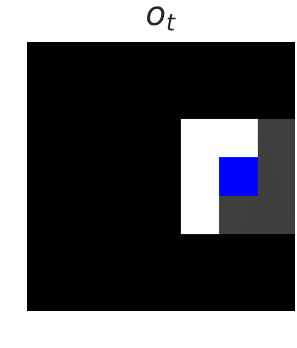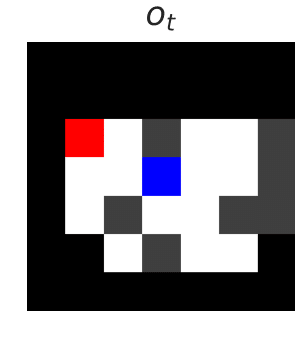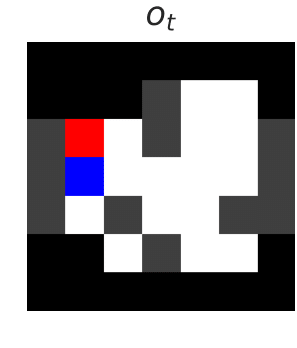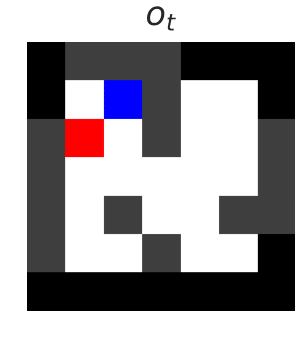
We want to develop reinforcement learning (RL) agents that can be trusted to act in high-stakes situations in the real world. That means we need to generalize about common dangers that we might have experienced before, but in an unseen setting. For example, we know it is dangerous to touch a hot oven, even if it’s in a room we haven’t been in before. …
Full post...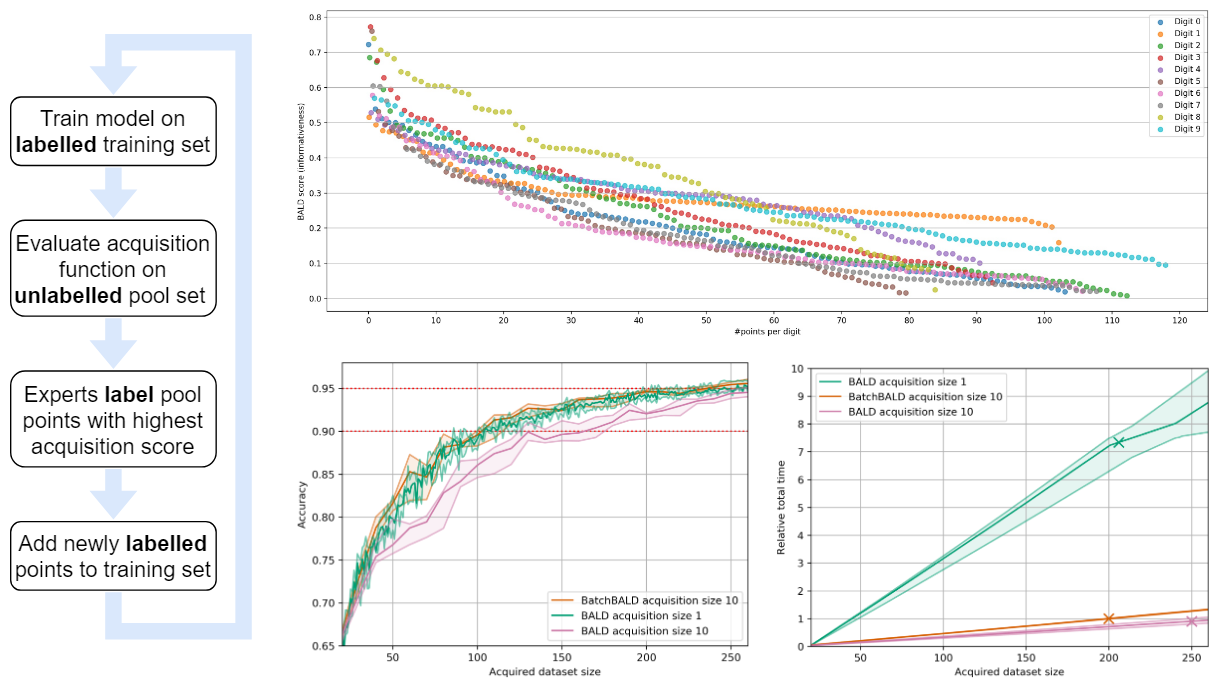
In Active Learning we use a “human in the loop” approach to data labelling, reducing the amount of data that needs to be labelled drastically, and making machine learning applicable when labelling costs would be too high otherwise. In our paper [1] we present BatchBALD: a new practical method for choosing batches of informative points in Deep Active Learning which avoids labelling redundancies that plague existing methods. Our approach is based on information theory and expands on useful intuitions. We have also made our implementation available on GitHub at https://github.com/BlackHC/BatchBALD. …
Full post...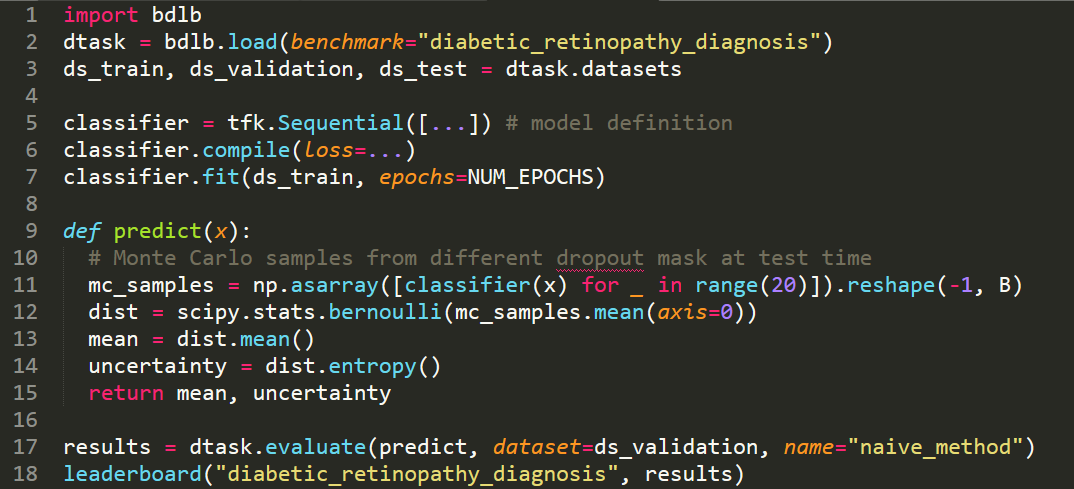
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints. …
Full post...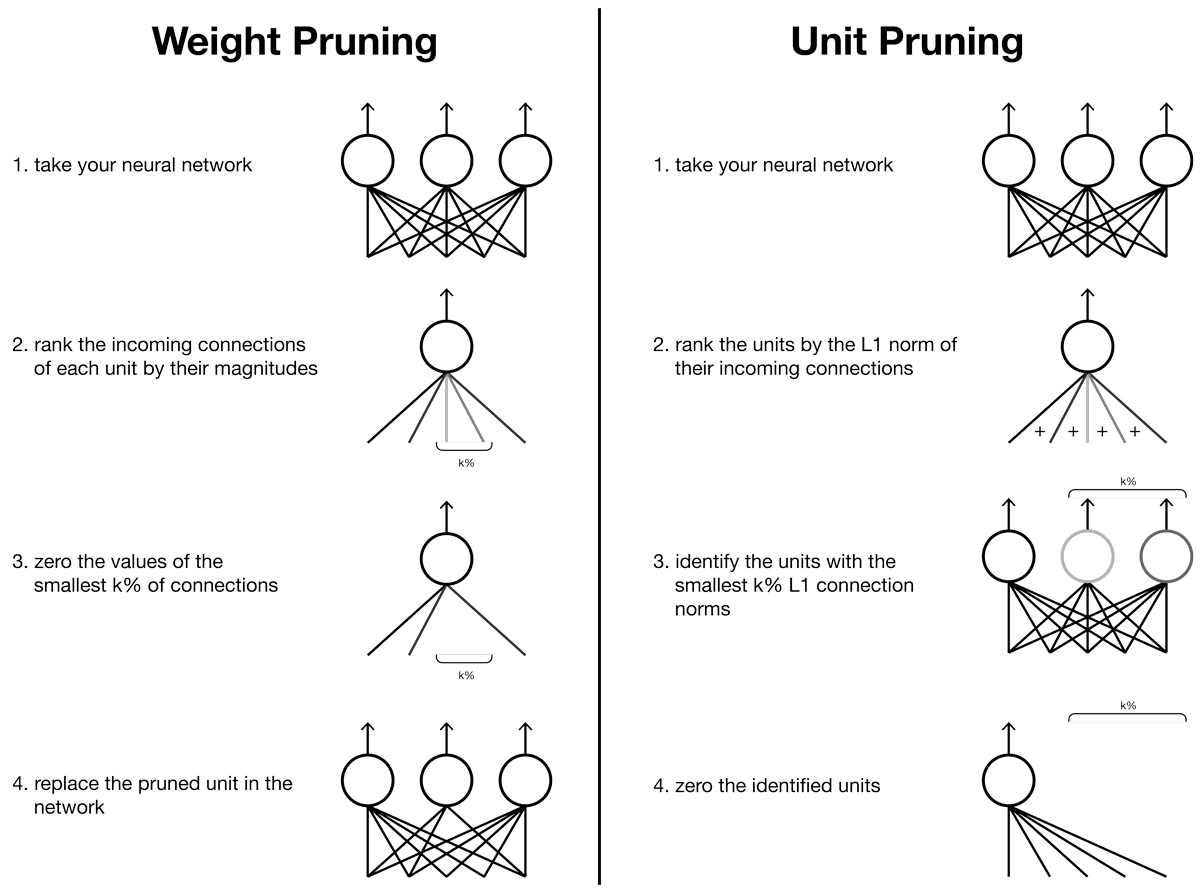
Neural networks can represent functions to solve complex tasks that are difficult — if not impossible — to write instructions for by hand, such as understanding language and recognizing objects. Conveniently, we’ve seen that task performance increases as we use larger networks. However, the increase in computational costs also increases dollars and time required to train and use models. Practitioners are plagued with networks that are too large to store in on-device memory, or too slow for real-world utility. …
Full post...
The applications of probably approximately correct (PAC) learning results to deep networks have historically been about as interesting as they sound. For neural networks of the scale used in practical applications, bounds involving concepts like VC dimension conclude that the algorithm will have no more than a certain error rate on the test set with probability at least zero. Recently, some work by Dziugaite and Roy, along with some folks from Columbia has managed to obtain non-vacuous generalization bounds for more realistic problems using a concept introduced by McAllester (1999) called PAC Bayes bounds. …
Full post...