Back to all members...
Zac Kenton
Postdoc (2018—2019)

Zac was a Postdoc in OATML working with Yarin Gal. His primary research interest is technical AI safety, and is currently working on robustness and safe exploration in reinforcement learning. He was previously a Research Assistant with Owain Evans at the Future of Humanity Institute, University of Oxford and a Visiting Researcher at the Montreal Institute for Learning Algorithms (MILA), under Yoshua Bengio. He also worked as a Data Scientist at ASI Data Science. He completed his PhD at Queen Mary University of London in Theoretical Physics, where he worked on string theory and cosmology. Prior to his PhD, he studied Mathematics at the University of Cambridge. After OATML, Zac joined the DeepMind AGI safety team.
Publications while at OATML • News items mentioning Zac Kenton • Reproducibility and Code • Blog Posts
Publications while at OATML:

A Systematic Comparison of Bayesian Deep Learning Robustness in Diabetic Retinopathy Tasks
Evaluation of Bayesian deep learning (BDL) methods is challenging. We often seek to evaluate the methods' robustness and scalability, assessing whether new tools give 'better' uncertainty estimates than old ones. These evaluations are paramount for practitioners when choosing BDL tools on-top of which they build their applications. Current popular evaluations of BDL methods, such as the UCI experiments, are lacking: Methods that excel with these experiments often fail when used in application such as medical or automotive, suggesting a pertinent need for new benchmarks in the field. We propose a new BDL benchmark with a diverse set of tasks, inspired by a real-world medical imaging application on diabetic retinopathy diagnosis. Visual inputs (512x512 RGB images of retinas) are considered, where model uncertainty is used for medical pre-screening---i.e. to refer patients to an expert when model diagnosis is uncertain. Methods are then ranked according to metrics derived from expert-... [full abstract]
Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Arnoud de Kroon, Yarin Gal
Spotlight talk, NeurIPS Workshop on Bayesian Deep Learning, 2019
[Preprint] [Code] [BibTex]

Generalizing from a few environments in safety-critical reinforcement learning
Before deploying autonomous agents in the real world, we need to be confident they will perform safely in novel situations. Ideally, we would expose agents to a very wide range of situations during training (e.g. many simulated environments), allowing them to learn about every possible danger. But this is often impractical: simulations may fail to capture the full range of situations and may differ subtly from reality. This paper investigates generalizing from a limited number of training environments in deep reinforcement learning. Our experiments test whether agents can perform safely in novel environments, given varying numbers of environments at train time. Using a gridworld setting, we find that standard deep RL agents do not reliably avoid catastrophes on unseen environments – even after performing near optimally on 1000 training environments. However, we show that catastrophes can be significantly reduced (but not eliminated) with simple modifications, including Q-network en... [full abstract]
Zac Kenton, Angelos Filos, Owain Evans, Yarin Gal
ICLR 2019 Workshop on Safe Machine Learning
[paper]
News items mentioning Zac Kenton:

Six group members honoured as NeurIPS top reviewers
07 Sep 2019
Six group members honoured as top reviewers at NeurIPS 2019: 2 members among the top 400 highest scoring reviewers and awarded free registration (Tim G. J. Rudner and Sebastian Farquhar), and 4 among the top 50% reviewers (Zac Kenton, Andreas Kirsch, Angelos Filos and Joost van Amersfoort).

Reproducibility and Code

Code for Bayesian Deep Learning Benchmarks
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints.
CodeAngelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Yarin Gal
Blog Posts

25 OATML Conference and Workshop papers at NeurIPS 2019
We are glad to share the following 25 papers by OATML authors and collaborators to be presented at this NeurIPS conference and workshops. …
Full post...Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Tom Rainforth, Panagiotis Tigas, Andreas Kirsch, Clare Lyle, Joost van Amersfoort, Yarin Gal, 08 Dec 2019
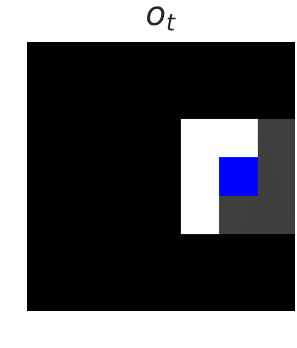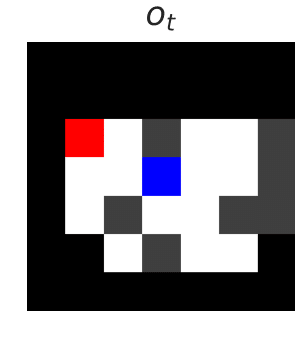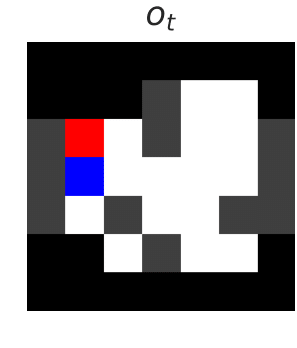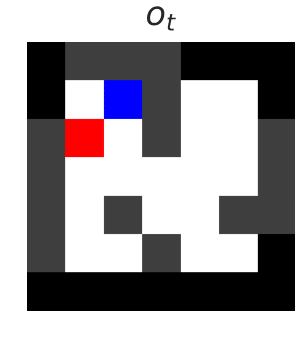
Poor generalization can be dangerous in RL!
We want to develop reinforcement learning (RL) agents that can be trusted to act in high-stakes situations in the real world. That means we need to generalize about common dangers that we might have experienced before, but in an unseen setting. For example, we know it is dangerous to touch a hot oven, even if it’s in a room we haven’t been in before. …
Full post...Zac Kenton, Angelos Filos, Yarin Gal, 02 Jul 2019
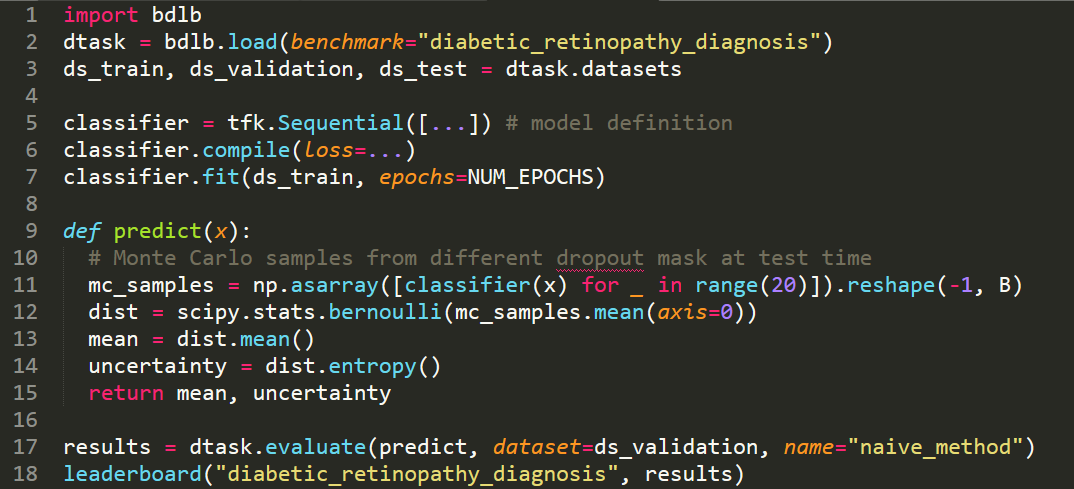
Bayesian Deep Learning Benchmarks
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints. …
Full post...Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Yarin Gal, 14 Jun 2019