Back to all members...
Tim G. J. Rudner
PhD (2017—2024)

Tim was co-supervised by Yarin Gal and Yee Whye Teh. His research interests span variational inference, reinforcement learning, Bayesian deep learning, and AI safety. Tim obtained a master’s degree in statistics from the University of Oxford and an undergraduate degree in mathematics and economics from Yale University, where he received the Charles E. Clark Memorial Award for Academic Excellence. During his DPhil, Tim was a Visiting Fellow at the University of California, Berkeley and Yale University. He is also an AI Fellow at Georgetown University’s Center for Security and Emerging Technology, a Fellow of the German Academic Scholarship Foundation, recipient of the Qualcomm Innovation Fellowship, and a Rhodes Scholar.
Publications while at OATML • News items mentioning Tim G. J. Rudner • Reproducibility and Code • Blog Posts
Publications while at OATML:

Pre-trained Text-to-Image Diffusion Models Are Versatile Representation Learners for Control
Embodied AI agents require a fine-grained understanding of the physical world mediated through visual and language inputs. Such capabilities are difficult to learn solely from task-specific data. This has led to the emergence of pre-trained vision-language models as a tool for transferring representations learned from internet-scale data to downstream tasks and new domains. However, commonly used contrastively trained representations such as in CLIP have been shown to fail at enabling embodied agents to gain a sufficiently fine-grained scene understanding -- a capability vital for control. To address this shortcoming, we consider representations from pre-trained text-to-image diffusion models, which are explicitly optimized to generate images from text prompts and as such, contain text-conditioned representations that reflect highly fine-grained visuo-spatial information. Using pre-trained text-to-image diffusion models, we construct Stable Control Representations which allow learn... [full abstract]
Gunshi Gupta, Karmesh Yadav, Yarin Gal, Dhruv Batra, Zsolt Kira, Cong Lu, Tim G. J. Rudner
ICLR Workshop on Generative Models for Decision Making, 2024
[paper]

Drug Discovery under Covariate Shift with Domain-Informed Prior Distributions over Functions
Accelerating the discovery of novel and more effective therapeutics is a major pharmaceutical problem in which deep learning plays an increasingly important role. However, drug discovery tasks are often characterized by a scarcity of labeled data and significant covariate shift---settings that are challenging for standard deep learning methods. In this paper, we address this challenge by developing a probabilistic model that is able to encode prior knowledge about the data-generating process into a prior distribution over functions, allowing researchers to explicitly specify relevant information about the modeled domain. We evaluate this method on a novel, high-quality antimalarial dataset that facilitates the robust comparison of models in an extrapolative regime and demonstrate that integrating explicit prior knowledge of drug-like chemical space into the modeling process substantially improves both the predictive accuracy and the uncertainty estimates of deep learning algorithms... [full abstract]
Leo Klarner, Tim G. J. Rudner, Michael Reutlinger, Torsten Schindler, Garrett M Morris, Charlotte Deane, Yee Whye Teh
ICML, 2023
[OpenReview] [BibTex]

Can Active Sampling Reduce Causal Confusion in Offline Reinforcement Learning?
Causal confusion is a phenomenon where an agent learns a policy that reflects imperfect spurious correlations in the data. Such a policy may falsely appear to be optimal during training if most of the training data contain such spurious correlations. This phenomenon is particularly pronounced in domains such as robotics, with potentially large gaps between the open- and closed-loop performance of an agent. In such settings, causally confused models may appear to perform well according to open-loop metrics during training but fail catastrophically when deployed in the real world. In this paper, we study causal confusion in offline reinforcement learning. We investigate whether selectively sampling appropriate points from a dataset of demonstrations may enable offline reinforcement learning agents to disambiguate the underlying causal mechanisms of the environment, alleviate causal confusion in offline reinforcement learning, and produce a safer model for deployment. To answer this q... [full abstract]
Gunshi Gupta, Tim G. J. Rudner, Rowan McAllister, Adrien Gaidon, Yarin Gal
CLeaR, 2023
NeurIPS Workshop on Causal Machine Learning for Real-World Impact, 2022
[OpenReview] [BibTex]
Tractable Function-Space Variational Inference in Bayesian Neural Networks
Reliable predictive uncertainty estimation plays an important role in enabling the deployment of neural networks to safety-critical settings. A popular approach for estimating the predictive uncertainty of neural networks is to define a prior distribution over the network parameters, infer an approximate posterior distribution, and use it to make stochastic predictions. However, explicit inference over neural network parameters makes it difficult to incorporate meaningful prior information about the data-generating process into the model. In this paper, we pursue an alternative approach. Recognizing that the primary object of interest in most settings is the distribution over functions induced by the posterior distribution over neural network parameters, we frame Bayesian inference in neural networks explicitly as inferring a posterior distribution over functions and propose a scalable function-space variational inference method that allows incorporating prior information and resul... [full abstract]
Tim G. J. Rudner, Zonghao Chen, Yee Whye Teh, Yarin Gal
NeurIPS, 2022
ICML Workshop on Uncertainty & Robustness in Deep Learning, 2021
[OpenReview] [BibTex]

Plex: Towards Reliability using Pretrained Large Model Extensions
A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language mo... [full abstract]
Dustin Tran, Jeremiah Liu, Michael W. Dusenberry, Du Phan, Mark Collier, Jie Ren, Kehang Han, Zi Wang, Zelda Mariet, Huiyi Hu, Neil Band, Tim G. J. Rudner, Karan Singhal, Zachary Nado, Joost van Amersfoort, Andreas Kirsch, Rodolphe Jenatton, Nithum Thain, Honglin Yuan, Kelly Buchanan, Kevin Murphy, D. Sculley, Yarin Gal, Zoubin Ghahramani, Jasper Snoek, Balaji Lakshminarayan
Contributed Talk, ICML Pre-training Workshop, 2022
[OpenReview] [Code] [BibTex] [Google AI Blog Post]

Continual Learning via Sequential Function-Space Variational Inference
Sequential Bayesian inference over predictive functions is a natural framework for continual learning from streams of data. However, applying it to neural networks has proved challenging in practice. Addressing the drawbacks of existing techniques, we propose an optimization objective derived by formulating continual learning as sequential function-space variational inference. In contrast to existing methods that regularize neural network parameters directly, this objective allows parameters to vary widely during training, enabling better adaptation to new tasks. Compared to objectives that directly regularize neural network predictions, the proposed objective allows for more flexible variational distributions and more effective regularization. We demonstrate that, across a range of task sequences, neural networks trained via sequential function-space variational inference achieve better predictive accuracy than networks trained with related methods while depending less on maintain... [full abstract]
Tim G. J. Rudner, Freddie Bickford Smith, Qixuan Feng, Yee Whye Teh, Yarin Gal
ICML, 2022
ICML Workshop on Theory and Foundations of Continual Learning, 2021
[Paper] [BibTex]
Challenges and Opportunities in Offline Reinforcement Learning from Visual Observations
Offline reinforcement learning has shown great promise in leveraging large pre-collected datasets for policy learning, allowing agents to forgo often-expensive online data collection. However, to date, offline reinforcement learning from visual observations with continuous action spaces has been relatively under-explored, and there is a lack of understanding of where the remaining challenges lie. In this paper, we seek to establish simple baselines for continuous control in the visual domain. We show that simple modifications to two state-of-the-art vision-based online reinforcement learning algorithms, DreamerV2 and DrQ-v2, suffice to outperform prior work and establish a competitive baseline. We rigorously evaluate these algorithms on both existing offline datasets and a new testbed for offline reinforcement learning from visual observations that better represents the data distributions present in real-world offline RL problems, and open-source our code and data to facilitate pro... [full abstract]
Cong Lu, Philip J. Ball, Tim G. J. Rudner, Jack Parker-Holder, Michael A. Osborne, Yee Whye Teh
Outstanding Paper Award, RSS Workshop on Learning from Diverse, Offline Data, 2022
ICML Workshop on Decision Awareness in Reinforcement Learning, 2022
[arXiv] [BibTex]

On Pathologies in KL-Regularized Reinforcement Learning from Expert Demonstrations
KL-regularized reinforcement learning from expert demonstrations has proved successful in improving the sample efficiency of deep reinforcement learning algorithms, allowing them to be applied to challenging physical real-world tasks. However, we show that KL-regularized reinforcement learning with behavioral policies derived from expert demonstrations suffers from hitherto unrecognized pathological behavior that can lead to slow, unstable, and suboptimal online training. We show empirically that the pathology occurs for commonly chosen behavioral policy classes and demonstrate its impact on sample efficiency and online policy performance. Finally, we show that the pathology can be remedied by specifying non-parametric behavioral policies and that doing so allows KL-regularized RL to significantly outperform state-of-the-art approaches on a variety of challenging locomotion and dexterous hand manipulation tasks.
Tim G. J. Rudner, Cong Lu, Michael A. Osborne, Yarin Gal, Yee Whye Teh
NeurIPS, 2021
ICLR Workshop on Robust and Reliable Machine Learning in the Real World, 2021
[OpenReview] [Website] [BibTex]

Outcome-Driven Reinforcement Learning via Variational Inference
While reinforcement learning algorithms provide automated acquisition of optimal policies, practical application of such methods requires a number of design decisions, such as manually designing reward functions that not only define the task, but also provide sufficient shaping to accomplish it. In this paper, we view reinforcement learning as inferring policies that achieve desired outcomes, rather than as a problem of maximizing rewards. To solve this inference problem, we establish a novel variational inference formulation that allows us to derive a well-shaped reward function which can be learned directly from environment interactions. From the corresponding variational objective, we also derive a new probabilistic Bellman backup operator and use it to develop an off-policy algorithm to solve goal-directed tasks. We empirically demonstrate that this method eliminates the need to hand-craft reward functions for a suite of diverse manipulation and locomotion tasks and leads to ef... [full abstract]
Tim G. J. Rudner, Vitchyr H. Pong, Rowan McAllister, Yarin Gal, Sergey Levine
NeurIPS, 2021
NeurIPS Workshop on Deep Reinforcement Learning, 2020
[arXiv] [OpenReview] [BibTex]

Benchmarking Bayesian Deep Learning on Diabetic Retinopathy Detection Tasks
Bayesian deep learning seeks to equip deep neural networks with the ability to precisely quantify their predictive uncertainty, and has promised to make deep learning more reliable for safety-critical real-world applications. Yet, existing Bayesian deep learning methods fall short of this promise; new methods continue to be evaluated on unrealistic test beds that do not reflect the complexities of downstream real-world tasks that would benefit most from reliable uncertainty quantification. We propose a set of real-world tasks that accurately reflect such complexities and are designed to assess the reliability of predictive models in safety-critical scenarios. Specifically, we curate two publicly available datasets of high-resolution human retina images exhibiting varying degrees of diabetic retinopathy, a medical condition that can lead to blindness, and use them to design a suite of automated diagnosis tasks that require reliable predictive uncertainty quantification. We use these... [full abstract]
Neil Band, Tim G. J. Rudner, Qixuan Feng, Angelos Filos, Zachary Nado, Michael W. Dusenberry, Ghassen Jerfel, Dustin Tran, Yarin Gal
NeurIPS Datasets and Benchmarks Track, 2021
Spotlight Talk, NeurIPS Workshop on Distribution Shifts, 2021
Symposium on Machine Learning for Health (ML4H) Extended Abstract Track, 2021
NeurIPS Workshop on Bayesian Deep Learning, 2021
[OpenReview] [Code] [BibTex]

Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
High-quality estimates of uncertainty and robustness are crucial for numerous real-world applications, especially for deep learning which underlies many deployed ML systems. The ability to compare techniques for improving these estimates is therefore very important for research and practice alike. Yet, competitive comparisons of methods are often lacking due to a range of reasons, including: compute availability for extensive tuning, incorporation of sufficiently many baselines, and concrete documentation for reproducibility. In this paper we introduce Uncertainty Baselines: high-quality implementations of standard and state-of-the-art deep learning methods on a variety of tasks. As of this writing, the collection spans 19 methods across 9 tasks, each with at least 5 metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components. Our goal is to provide immediate starting points for experimentation with new methods or applications. Addi... [full abstract]
Zachary Nado, Neil Band, Mark Collier, Josip Djolonga, Michael W. Dusenberry, Sebastian Farquhar, Angelos Filos, Marton Havasi, Rodolphe Jenatton, Ghassen Jerfel, Jeremiah Liu, Zelda Mariet, Jeremy Nixon, Shreyas Padhy, Jie Ren, Tim G. J. Rudner, Yeming Wen, Florian Wenzel, Kevin Murphy, D. Sculley, Balaji Lakshminarayanan, Jasper Snoek, Yarin Gal, Dustin Tran
NeurIPS Workshop on Bayesian Deep Learning, 2021
[arXiv] [Code] [Blog Post (Google AI)] [BibTex]

On Signal-to-Noise Ratio Issues in Variational Inference for Deep Gaussian Processes
We show that the gradient estimates used in training Deep Gaussian Processes (DGPs) with importance-weighted variational inference are susceptible to signal-to-noise ratio (SNR) issues. Specifically, we show both theoretically and empirically that the SNR of the gradient estimates for the latent variable's variational parameters decreases as the number of importance samples increases. As a result, these gradient estimates degrade to pure noise if the number of importance samples is too large. To address this pathology, we show how doubly-reparameterized gradient estimators, originally proposed for training variational autoencoders, can be adapted to the DGP setting and that the resultant estimators completely remedy the SNR issue, thereby providing more reliable training. Finally, we demonstrate that our fix can lead to improvements in the predictive performance of the model's predictive posterior.
Tim G. J. Rudner, Oscar Key, Yarin Gal, Tom Rainforth
ICML, 2021
[arXiv] [Code] [BibTex]

Inter-domain Deep Gaussian Processes
Inter-domain Gaussian processes (GPs) allow for high flexibility and low computational cost when performing approximate inference in GP models. They are particularly suitable for modeling data exhibiting global structure but are limited to stationary covariance functions and thus fail to model non-stationary data effectively. We propose Inter-domain Deep Gaussian Processes, an extension of inter-domain shallow GPs that combines the advantages of inter-domain and deep Gaussian processes (DGPs), and demonstrate how to leverage existing approximate inference methods to perform simple and scalable approximate inference using inter-domain features in DGPs. We assess the performance of our method on a range of regression tasks and demonstrate that it outperforms inter-domain shallow GPs and conventional DGPs on challenging large-scale real-world datasets exhibiting both global structure as well as a high-degree of non-stationarity.
Tim G. J. Rudner, Dino Sejdinovic, Yarin Gal
ICML, 2020
[arXiv] [Website] [Talk] [Slides] [BibTex]

The Natural Neural Tangent Kernel: Neural Network Training Dynamics under Natural Gradient Descent
Gradient-based optimization methods have proven successful in learning complex, overparameterized neural networks from non-convex objectives. Yet, the precise theoretical relationship between gradient-based optimization methods, the resulting training dynamics, and generalization in deep neural networks (DNNs) remains unclear. In this work, we investigate the training dynamics of overparameterized DNNs of \emph{finite-width} under natural gradient descent. To do so, we take a function-space view of the training dynamics under natural gradient descent and derive a bound on the discrepancy between the DNN predictive distributions induced by linearized and non-linearized natural gradient descent. Unlike prior work, our bound quantifies the extent to which linearization of the training dynamics of finite-width DNNs affects DNN predictions on arbitrary test points.
Tim G. J. Rudner, Florian Wenzel, Yee Whye Teh, Yarin Gal
Contributed talk, NeurIPS Workshop on Bayesian Deep Learning, 2019
[Preprint]

A Systematic Comparison of Bayesian Deep Learning Robustness in Diabetic Retinopathy Tasks
Evaluation of Bayesian deep learning (BDL) methods is challenging. We often seek to evaluate the methods' robustness and scalability, assessing whether new tools give 'better' uncertainty estimates than old ones. These evaluations are paramount for practitioners when choosing BDL tools on-top of which they build their applications. Current popular evaluations of BDL methods, such as the UCI experiments, are lacking: Methods that excel with these experiments often fail when used in application such as medical or automotive, suggesting a pertinent need for new benchmarks in the field. We propose a new BDL benchmark with a diverse set of tasks, inspired by a real-world medical imaging application on diabetic retinopathy diagnosis. Visual inputs (512x512 RGB images of retinas) are considered, where model uncertainty is used for medical pre-screening---i.e. to refer patients to an expert when model diagnosis is uncertain. Methods are then ranked according to metrics derived from expert-... [full abstract]
Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Arnoud de Kroon, Yarin Gal
Spotlight talk, NeurIPS Workshop on Bayesian Deep Learning, 2019
[Preprint] [Code] [BibTex]

VIREL: A Variational Inference Framework for Reinforcement Learning
Applying probabilistic models to reinforcement learning (RL) enables the application of powerful optimisation tools such as variational inference to RL. However, existing inference frameworks and their algorithms pose significant challenges for learning optimal policies, e.g., the absence of mode capturing behaviour in pseudo-likelihood methods and difficulties learning deterministic policies in maximum entropy RL based approaches. We propose VIREL, a novel, theoretically grounded probabilistic inference framework for RL that utilises a parametrised action-value function to summarise future dynamics of the underlying MDP. This gives VIREL a mode-seeking form of KL divergence, the ability to learn deterministic optimal polices naturally from inference and the ability to optimise value functions and policies in separate, iterative steps. In applying variational expectation-maximisation to VIREL we thus show that the actor-critic algorithm can be reduced to expectation-maximisation, w... [full abstract]
Matthew Fellows, Anuj Mahajan, Tim G. J. Rudner, Shimon Whiteson
NeurIPS, 2019
NeurIPS 2018 Workshop on Probabilistic Reinforcement Learning and Structured Control
[arXiv] [BibTex]

The StarCraft Multi-Agent Challenge
In the last few years, deep multi-agent reinforcement learning (RL) has become a highly active area of research. A particularly challenging class of problems in this area is partially observable, cooperative, multi-agent learning, in which teams of agents must learn to coordinate their behaviour while conditioning only on their private observations. This is an attractive research area since such problems are relevant to a large number of real-world systems and are also more amenable to evaluation than general-sum problems. Standardised environments such as the ALE and MuJoCo have allowed single-agent RL to move beyond toy domains, such as grid worlds. However, there is no comparable benchmark for cooperative multi-agent RL. As a result, most papers in this field use one-off toy problems, making it difficult to measure real progress. In this paper, we propose the StarCraft Multi-Agent Challenge (SMAC) as a benchmark problem to fill this gap. SMAC is based on the popular real-time st... [full abstract]
Mikayel Samvelyan, Tabish Rashid, Christian Schroeder de Witt, Gregory Farquhar, Nantas Nardelli, Tim G. J. Rudner, Chia-Man Hung, Philip H. S. Torr, Jakob Foerster, Shimon Whiteson
AAMAS 2019
NeurIPS 2019 Workshop on Deep Reinforcement Learning
[arXiv] [Code] [BibTex] [Media]

Multi³Net: Segmenting Flooded Buildings via Fusion of Multiresolution, Multisensor, and Multitemporal Satellite Imagery
We propose a novel approach for rapid segmentation of flooded buildings by fusing multiresolution, multisensor, and multitemporal satellite imagery in a convolutional neural network. Our model significantly expedites the generation of satellite imagery-based flood maps, crucial for first responders and local authorities in the early stages of flood events. By incorporating multitemporal satellite imagery, our model allows for rapid and accurate post-disaster damage assessment and can be used by governments to better coordinate medium- and long-term financial assistance programs for affected areas. The network consists of multiple streams of encoder-decoder architectures that extract spatiotemporal information from medium-resolution images and spatial information from high-resolution images before fusing the resulting representations into a single medium-resolution segmentation map of flooded buildings. We compare our model to state-of-the-art methods for building footprint segmenta... [full abstract]
Tim G. J. Rudner, Marc Rußwurm, Jakub Fil, Ramona Pelich, Benjamin Bischke, Veronika Kopackova, Piotr Bilinski
AAAI 2019
NeurIPS 2018 Workshop AI for Social Good
[arXiv] [Code] [BibTex] [Media]

On the Connection between Neural Processes and Gaussian Processes with Deep Kernels
Neural Processes (NPs) are a class of neural latent variable models that combine desirable properties of Gaussian Processes (GPs) and neural networks. Like GPs, NPs define distributions over functions and are able to estimate the uncertainty in their predictions. Like neural networks, NPs are computationally efficient during training and prediction time. We establish a simple and explicit connection between NPs and GPs. In particular, we show that, under certain conditions, NPs are mathematically equivalent to GPs with deep kernels. This result further elucidates the relationship between GPs and NPs and makes previously derived theoretical insights about GPs applicable to NPs. Furthermore, it suggests a novel approach to learning expressive GP covariance functions applicable across different prediction tasks by training a deep kernel GP on a set of datasets
Tim G. J. Rudner, Vincent Fortuin, Yee Whye Teh, Yarin Gal
NeurIPS Workshop on Bayesian Deep Learning, 2018
[Paper] [BibTex]
News items mentioning Tim G. J. Rudner:

Gunshi Gupta presents work at ICLR 2024 GenAI4DM workshop
11 May 2024
OATML student Gunshi Gupta was invited to present recent work along with collaborators from Georgia Tech and NYU (including group member Tim Rudner) at the Generative AI for Decision Making workshop (GenAI4DM) at ICLR 2024. The talk was on the paper ‘Pretrained Text-to-Image Diffusion Models Are Versatile Representation Learners for Control’. Read the paper here.


NeurIPS 2021
11 Oct 2021
Thirteen papers with OATML members accepted to NeurIPS 2021 main conference. More information in our blog post.

OATML graduate students receive best reviewer awards and serve as expert reviewers at ICML 2021
06 Sep 2021
OATML graduate students Sebastian Farquhar and Jannik Kossen receive best reviewer awards (top 10%) at ICML 2021. Further, OATML graduate students Tim G. J. Rudner, Pascal Notin, Panagiotis Tigas, and Binxin Ru have served the conference as expert reviewers.
ICML 2021
17 Jul 2021
Seven papers with OATML members accepted to ICML 2021, together with 14 workshop papers. More information in our blog post.

OATML graduate students receive Outstanding Reviewer Awards
03 Jun 2021
OATML graduate students Pascal Notin and Tim G. J. Rudner received best reviewer awards (top 5%) at UAI 2021.

Tim G. J. Rudner awarded Qualcomm Innovation Fellowship
19 May 2021
Tim G. J. Rudner is one of 4 PhD students awarded the 2021 Qualcomm Innovation Fellowship Europe. Congratulations to the winners!
Tim G. J. Rudner releases paper series on AI safety
17 Mar 2021
OATML graduate student Tim G. J. Rudner wrote a paper series on AI safety for non-experts (An Overview, Robustness, Interpretability).
OATML researcher to speak at Max Planck Institute & UCLA
17 Dec 2020
OATML graduate student Tim G. J. Rudner will give an invited talk on Outcome-Driven Reinforcement Learning via Variational Inference at the MPI+UCLA Mathematical Machine Learning Seminar. Professor Yarin Gal and collaborator Sergey Levine are also co-authors on the paper.
Tim G. J. Rudner to speak at Center for Security & Emerging Technology
16 Dec 2020
OATML graduate student Tim G. J. Rudner will give an invited talk on “A Non-technical Guide to Modern Machine Learning” at the Georgetown University’s Center for Security & Emerging Technology.
Tim G. J. Rudner to give guest lecture at UCL
16 Dec 2020
OATML graduate student Tim G. J. Rudner will give an invited guest lecture on Bayesian Deep Learning at University College London.

Oxford-Google Workshop on Reliable Machine Learning
24 Nov 2020
OATML hosted a joint workshop with Google Research on reliable machine learning with a series of talks and breakout sessions. The event was organized by OATML graduate student Tim G. J. Rudner and Mario Lučić at Google.
Tim G. J. Rudner receives Outstanding Reviewer Award
01 Nov 2020
OATML graduate student Tim G. J. Rudner received a best reviewer award (top 10%) at NeurIPS 2020.
OATML student to speak at University of Cambridge
16 Oct 2020
OATML graduate student Tim G. J. Rudner will give an invited talk about his work with Professor Yarin Gal on Inter-domain Deep Gaussian Processes at the University of Cambridge’s ML@CS Seminar.
OATML researcher invited to join OECD AI Working Groups
01 Oct 2020
OATML graduate student Tim G. J. Rudner has joined the OECD’s Working Groups on Trustworthy AI and AI Classification as an invited expert.
Tim G. J. Rudner to speak at UCL Centre for AI
13 Aug 2020
OATML graduate student Tim G. J. Rudner will give an invited talk on Inter-domain Deep Gaussian Processes at the UCL Centre for AI’s Statistical Machine Learning Seminar.

Bayesian deep learning for all humankind
14 Jan 2020
Our work with NASA and ESA over the past few years, together with Lewis Smith and Tim G. J. Rudner, is summarised in a recent article written by James Parr. Read more in Inspired: Bayesian deep learning for all humankind
Six group members honoured as NeurIPS top reviewers
07 Sep 2019
Six group members honoured as top reviewers at NeurIPS 2019: 2 members among the top 400 highest scoring reviewers and awarded free registration (Tim G. J. Rudner and Sebastian Farquhar), and 4 among the top 50% reviewers (Zac Kenton, Andreas Kirsch, Angelos Filos and Joost van Amersfoort).
OATML students received ICML 2019 Outstanding Reviewer Awards
02 Jun 2019
OATML DPhil students Lewis Smith and Tim G. J. Rudner received ICML 2019 Outstanding Reviewer Awards (top 5% of reviewers).
Reproducibility and Code

Code for Bayesian Deep Learning Benchmarks
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints.
CodeAngelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Yarin Gal
Code for Multi³Net (multitemporal satellite imagery segmentation)
We propose a novel approach for rapid segmentation of flooded buildings by fusing multiresolution, multisensor, and multitemporal satellite imagery in a convolutional neural network. Our model significantly expedites the generation of satellite imagery-based flood maps, crucial for first responders and local authorities in the early stages of flood events. By incorporating multitemporal satellite imagery, our model allows for rapid and accurate post-disaster damage assessment and can be used by governments to better coordinate medium- and long-term financial assistance programs for affected areas. The network consists of multiple streams of encoder-decoder architectures that extract spatiotemporal information from medium-resolution images and spatial information from high-resolution images before fusing the resulting representations into a single medium-resolution segmentation map of flooded buildings. We compare our model to state-of-the-art methods for building footprint segmentation as well as to alternative fusion approaches for the segmentation of flooded buildings and find that our model performs best on both tasks. We also demonstrate that our model produces highly accurate segmentation maps of flooded buildings using only publicly available medium-resolution data instead of significantly more detailed but sparsely available very high-resolution data. We release the first open-source dataset of fully preprocessed and labeled multiresolution, multispectral, and multitemporal satellite images of disaster sites along with our source code.
Code, PublicationTim G. J. Rudner, Marc Rußwurm, Jakub Fil, Ramona Pelich, Benjamin Bischke, Veronika Kopackova, Piotr Bilinski
Blog Posts

OATML Conference papers at NeurIPS 2022
OATML group members and collaborators are proud to present 8 papers at NeurIPS 2022 main conference, and 11 workshop papers. …
Full post...Yarin Gal, Freddie Kalaitzis, Shreshth Malik, Lorenz Kuhn, Gunshi Gupta, Jannik Kossen, Pascal Notin, Andrew Jesson, Panagiotis Tigas, Tim G. J. Rudner, Sebastian Farquhar, Ilia Shumailov, 25 Nov 2022

OATML at ICML 2022
OATML group members and collaborators are proud to present 11 papers at the ICML 2022 main conference and workshops. Group members are also co-organizing the Workshop on Computational Biology, and the Oxford Wom*n Social. …
Full post...Sören Mindermann, Jan Brauner, Muhammed Razzak, Andreas Kirsch, Aidan Gomez, Sebastian Farquhar, Pascal Notin, Tim G. J. Rudner, Freddie Bickford Smith, Neil Band, Panagiotis Tigas, Andrew Jesson, Lars Holdijk, Joost van Amersfoort, Kelsey Doerksen, Jannik Kossen, Yarin Gal, 17 Jul 2022

13 OATML Conference papers at NeurIPS 2021
OATML group members and collaborators are proud to present 13 papers at NeurIPS 2021 main conference. …
Full post...Jannik Kossen, Neil Band, Aidan Gomez, Clare Lyle, Tim G. J. Rudner, Yarin Gal, Binxin (Robin) Ru, Clare Lyle, Lisa Schut, Atılım Güneş Baydin, Tim G. J. Rudner, Andrew Jesson, Panagiotis Tigas, Joost van Amersfoort, Andreas Kirsch, Pascal Notin, Angelos Filos, 11 Oct 2021
21 OATML Conference and Workshop papers at ICML 2021
OATML group members and collaborators are proud to present 21 papers at ICML 2021, including 7 papers at the main conference and 14 papers at various workshops. Group members will also be giving invited talks and participate in panel discussions at the workshops. …
Full post...Angelos Filos, Clare Lyle, Jannik Kossen, Sebastian Farquhar, Tom Rainforth, Andrew Jesson, Sören Mindermann, Tim G. J. Rudner, Oscar Key, Binxin (Robin) Ru, Pascal Notin, Panagiotis Tigas, Andreas Kirsch, Jishnu Mukhoti, Joost van Amersfoort, Lisa Schut, Muhammed Razzak, Aidan Gomez, Jan Brauner, Yarin Gal, 17 Jul 2021
22 OATML Conference and Workshop papers at NeurIPS 2020
OATML group members and collaborators are proud to be presenting 22 papers at NeurIPS 2020. Group members are also co-organising various events around NeurIPS, including workshops, the NeurIPS Meet-Up on Bayesian Deep Learning and socials. …
Full post...Muhammed Razzak, Panagiotis Tigas, Angelos Filos, Atılım Güneş Baydin, Andrew Jesson, Andreas Kirsch, Clare Lyle, Freddie Kalaitzis, Jan Brauner, Jishnu Mukhoti, Lewis Smith, Lisa Schut, Mizu Nishikawa-Toomey, Oscar Key, Binxin (Robin) Ru, Sebastian Farquhar, Sören Mindermann, Tim G. J. Rudner, Yarin Gal, 04 Dec 2020
13 OATML Conference and Workshop papers at ICML 2020
We are glad to share the following 13 papers by OATML authors and collaborators to be presented at this ICML conference and workshops …
Full post...Angelos Filos, Sebastian Farquhar, Tim G. J. Rudner, Lewis Smith, Lisa Schut, Tom Rainforth, Panagiotis Tigas, Pascal Notin, Andreas Kirsch, Clare Lyle, Joost van Amersfoort, Jishnu Mukhoti, Yarin Gal, 10 Jul 2020
25 OATML Conference and Workshop papers at NeurIPS 2019
We are glad to share the following 25 papers by OATML authors and collaborators to be presented at this NeurIPS conference and workshops. …
Full post...Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Tom Rainforth, Panagiotis Tigas, Andreas Kirsch, Clare Lyle, Joost van Amersfoort, Yarin Gal, 08 Dec 2019
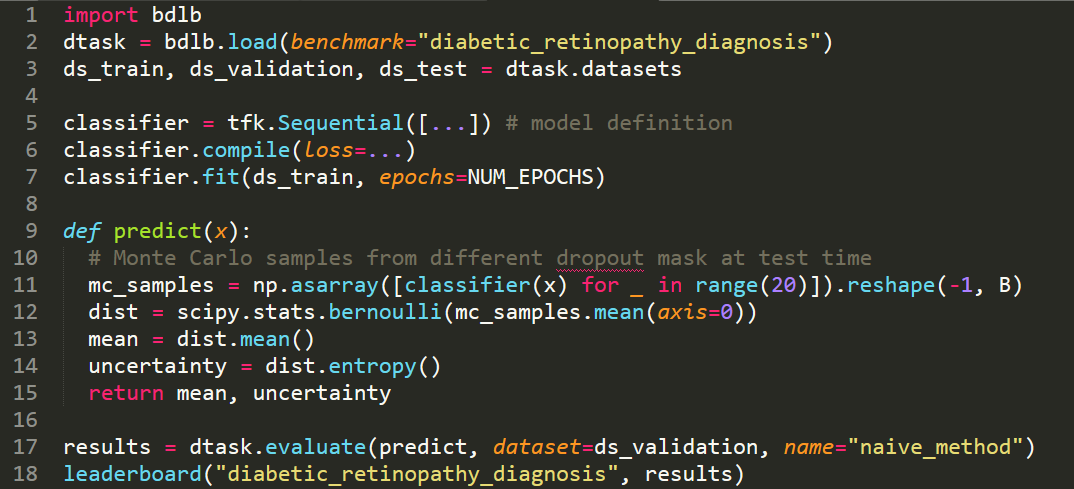
Bayesian Deep Learning Benchmarks
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints. …
Full post...Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Yarin Gal, 14 Jun 2019