Back to all members...
Sebastian Farquhar
Associate Member (Senior Research Fellow) (2017—2025)

Since 2022, Seb works as a research scientist at DeepMind’s safety team. He continues to work with OATML, co-supervising students with Yarin. Seb was a Junior Research Fellow in Computer Science at Christ Church, University of Oxford, an independent career-development research post. He finished his DPhil supervised by Yarin Gal and part of the Centre for Doctoral Training in Cyber Security. He is interested in understanding the role of approximation in Bayesian deep learning, and applications in medium- and long-term AI safety. Before joining the research group, he worked in technology policy (including biosafety and AI policy), social-entrepreneurship, and strategy consulting. He has been working on startups in the effective altruism community since 2012. He has a Masters degree in Physics and Philosophy from the University of Oxford.
Publications while at OATML • News items mentioning Sebastian Farquhar • Reproducibility and Code • Blog Posts
Publications while at OATML:

Do Multilingual LLMs Think In English?
Large language models (LLMs) have multilingual capabilities and can solve tasks across various languages. However, we show that current LLMs make key decisions in a representation space closest to English, regardless of their input and output languages. Exploring the internal representations with a logit lens for sentences in French, German, Dutch, and Mandarin, we show that the LLM first emits representations close to English for semantically-loaded words before translating them into the target language. We further show that activation steering in these LLMs is more effective when the steering vectors are computed in English rather than in the language of the inputs and outputs. This suggests that multilingual LLMs perform key reasoning steps in a representation that is heavily shaped by English in a way that is not transparent to system users.
Lisa Schut, Yarin Gal, Sebastian Farquhar
arXiv
[paper]

Detecting hallucinations in large language models using semantic entropy
Large language model (LLM) systems, such as ChatGPT or Gemini, can show impressive reasoning and question-answering capabilities but often ‘hallucinate’ false outputs and unsubstantiated answers. Answering unreliably or without the necessary information prevents adoption in diverse fields, with problems including fabrication of legal precedents or untrue facts in news articles and even posing a risk to human life in medical domains such as radiology. Encouraging truthfulness through supervision or reinforcement has only been partially successful. Researchers need a general method for detecting hallucinations in LLMs that works even with new and unseen questions to which humans might not know the answer. Here we develop new methods grounded in statistics, proposing entropy-based uncertainty estimators for LLMs to detect a subset of hallucinations—confabulations—which are arbitrary and incorrect generations. Our method addresses the fact that one idea can be expressed in many ways by... [full abstract]
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, Yarin Gal
Nature
[paper]

Prediction-Oriented Bayesian Active Learning
Information-theoretic approaches to active learning have traditionally focused on maximising the information gathered about the model parameters, most commonly by optimising the BALD score. We highlight that this can be suboptimal from the perspective of predictive performance. For example, BALD lacks a notion of an input distribution and so is prone to prioritise data of limited relevance. To address this we propose the expected predictive information gain (EPIG), an acquisition function that measures information gain in the space of predictions rather than parameters. We find that using EPIG leads to stronger predictive performance compared with BALD across a range of datasets and models, and thus provides an appealing drop-in replacement.
Freddie Bickford Smith, Andreas Kirsch, Sebastian Farquhar, Yarin Gal, Adam Foster, Tom Rainforth
International Conference on Artificial Intelligence and Statistics (AISTATS), 2023
[Paper] [BibTeX]

Semantic Uncertainty; Linguistic Invariances for Uncertainty Estimation in Natural Language Generation
We introduce a method to measure uncertainty in large language models. For tasks like question answering, it is essential to know when we can trust the natural language outputs of foundation models. We show that measuring uncertainty in natural language is challenging because of "semantic equivalence" -- different sentences can mean the same thing. To overcome these challenges we introduce semantic entropy -- an entropy which incorporates linguistic invariances created by shared meanings. Our method is unsupervised, uses only a single model, and requires no modifications to off-the-shelf language models. In comprehensive ablation studies we show that the semantic entropy is more predictive of model accuracy on question answering data sets than comparable baselines.
Lorenz Kuhn, Yarin Gal, Sebastian Farquhar
arXiv
[paper]

CLAM; Selective Clarification for Ambiguous Questions with Generative Language Models
Users often ask dialogue systems ambiguous questions that require clarification. We show that current language models rarely ask users to clarify ambiguous questions and instead provide incorrect answers. To address this, we introduce CLAM: a framework for getting language models to selectively ask for clarification about ambiguous user questions. In particular, we show that we can prompt language models to detect whether a given question is ambiguous, generate an appropriate clarifying question to ask the user, and give a final answer after receiving clarification. We also show that we can simulate users by providing language models with privileged information. This lets us automatically evaluate multi-turn clarification dialogues. Finally, CLAM significantly improves language models' accuracy on mixed ambiguous and unambiguous questions relative to SotA.
Lorenz Kuhn, Sebastian Farquhar, Yarin Gal
arXiv
[paper]

Discovering Agents
Causal models of agents have been used to analyse the safety aspects of machine learning systems. But identifying agents is non-trivial -- often the causal model is just assumed by the modeler without much justification -- and modelling failures can lead to mistakes in the safety analysis. This paper proposes the first formal causal definition of agents -- roughly that agents are systems that would adapt their policy if their actions influenced the world in a different way. From this we derive the first causal discovery algorithm for discovering agents from empirical data, and give algorithms for translating between causal models and game-theoretic influence diagrams. We demonstrate our approach by resolving some previous confusions caused by incorrect causal modelling of agents.
Zachary Kenton, Ramana Kumar, Sebastian Farquhar, Jonathan Richens, Matt MacDermott, Tom Everitt
arXiv
[paper]
Stochastic Batch Acquisition for Deep Active Learning
We provide a stochastic strategy for adapting well-known acquisition functions to allow batch active learning. In deep active learning, labels are often acquired in batches for efficiency. However, many acquisition functions are designed for single-sample acquisition and fail when naively used to construct batches. In contrast, state-of-the-art batch acquisition functions are costly to compute. We show how to extend single-sample acquisition functions to the batch setting. Instead of acquiring the top-K points from the pool set, we account for the fact that acquisition scores are expected to change as new points are acquired. This motivates simple stochastic acquisition strategies using score-based or rank-based distributions. Our strategies outperform the standard top-K acquisition with virtually no computational overhead and can be used as a drop-in replacement. In fact, they are even competitive with much more expensive methods despite their linear computational complexity. We c... [full abstract]
Andreas Kirsch, Sebastian Farquhar, Parmida Atighehchian, Andrew Jesson, Frederic Branchaud-Charron, Yarin Gal
ArXiv
[paper]

Prioritized Training on Points that are Learnable, Worth Learning, and not yet Learnt
Training on web-scale data can take months. But much computation and time is wasted on redundant and noisy points that are already learnt or not learnable. To accelerate training, we introduce Reducible Holdout Loss Selection (RHO-LOSS), a simple but principled technique which selects approximately those points for training that most reduce the model’s generalization loss. As a result, RHO-LOSS mitigates the weaknesses of existing data selection methods: techniques from the optimization literature typically select "hard" (e.g. high loss) points, but such points are often noisy (not learnable) or less task-relevant. Conversely, curriculum learning prioritizes "easy" points, but such points need not be trained on once learned. In contrast, RHO-LOSS selects points that are learnable, worth learning, and not yet learnt. RHO-LOSS trains in far fewer steps than prior art, improves accuracy, and speeds up training on a wide range of datasets, hyperparameters, and architectures (MLPs, CNNs... [full abstract]
Sören Mindermann, Jan Brauner, Muhammed Razzak, Mrinank Sharma, Andreas Kirsch, Winnie Xu, Benedikt Höltgen, Aidan Gomez, Adrien Morisot, Sebastian Farquhar, Yarin Gal
ICML, 2022 [Paper]

Active Surrogate Estimators: An Active Learning Approach to Label-Efficient Model Evaluation
We propose Active Surrogate Estimators (ASEs), a new method for label-efficient model evaluation. Evaluating model performance is a challenging and important problem when labels are expensive. ASEs address this active testing problem using a surrogate-based estimation approach, whereas previous methods have focused on Monte Carlo estimates. ASEs actively learn the underlying surrogate, and we propose a novel acquisition strategy, XWING, that tailors this learning to the final estimation task. We find that ASEs offer greater label-efficiency than the current state-of-the-art when applied to challenging model evaluation problems for deep neural networks. We further theoretically analyze ASEs' errors.
Jannik Kossen, Sebastian Farquhar, Yarin Gal, Tom Rainforth
NeurIPS 2022
[OpenReview] [arXiv]

Prospect Pruning: Finding Trainable Weights at Initialization using Meta-Gradients
Pruning neural networks at initialization would enable us to find sparse models that retain the accuracy of the original network while consuming fewer computational resources for training and inference. However, current methods are insufficient to enable this optimization and lead to a large degradation in model performance. In this paper, we identify a fundamental limitation in the formulation of current methods, namely that their saliency criteria look at a single step at the start of training without taking into account the trainability of the network. While pruning iteratively and gradually has been shown to improve pruning performance, explicit consideration of the training stage that will immediately follow pruning has so far been absent from the computation of the saliency criterion. To overcome the short-sightedness of existing methods, we propose Prospect Pruning (ProsPr), which uses meta-gradients through the first few steps of optimization to determine which weights to p... [full abstract]
Milad Alizadeh, Shyam A. Tailor, Luisa Zintgraf, Joost van Amersfoort, Sebastian Farquhar, Nicholas Donald Lane, Yarin Gal
ICLR, 2022 [arXiv] [OpenReview] [BibTex]
Evaluating Approximate Inference in Bayesian Deep Learning
Uncertainty representation is crucial to the safe and reliable deployment of deep learning. Bayesian methods provide a natural mechanism to represent epistemic uncertainty, leading to improved generalization and calibrated predictive distributions. Understanding the fidelity of approximate inference has extraordinary value beyond the standard approach of measuring generalization on a particular task: if approximate inference is working correctly, then we can expect more reliable and accurate deployment across any number of real-world settings. In this competition, we evaluate the fidelity of approximate Bayesian inference procedures in deep learning, using as a reference Hamiltonian Monte Carlo (HMC) samples obtained by parallelizing computations over hundreds of tensor processing unit (TPU) devices. We consider a variety of tasks, including image recognition, regression, covariate shift, and medical applications. All data are publicly available, and we release several baselines, i... [full abstract]
Andrew Gordon Wilson, Sanae Lotfi, Sharad Vikram, Matthew D Hoffman, Yarin Gal, Yingzhen Li, Melanie F Pradier, Andrew Foong, Sebastian Farquhar, Pavel Izmailov
Proceedings of Machine Learning Research, 176;113-114
[paper]

Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
High-quality estimates of uncertainty and robustness are crucial for numerous real-world applications, especially for deep learning which underlies many deployed ML systems. The ability to compare techniques for improving these estimates is therefore very important for research and practice alike. Yet, competitive comparisons of methods are often lacking due to a range of reasons, including: compute availability for extensive tuning, incorporation of sufficiently many baselines, and concrete documentation for reproducibility. In this paper we introduce Uncertainty Baselines: high-quality implementations of standard and state-of-the-art deep learning methods on a variety of tasks. As of this writing, the collection spans 19 methods across 9 tasks, each with at least 5 metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components. Our goal is to provide immediate starting points for experimentation with new methods or applications. Addi... [full abstract]
Zachary Nado, Neil Band, Mark Collier, Josip Djolonga, Michael W. Dusenberry, Sebastian Farquhar, Angelos Filos, Marton Havasi, Rodolphe Jenatton, Ghassen Jerfel, Jeremiah Liu, Zelda Mariet, Jeremy Nixon, Shreyas Padhy, Jie Ren, Tim G. J. Rudner, Yeming Wen, Florian Wenzel, Kevin Murphy, D. Sculley, Balaji Lakshminarayanan, Jasper Snoek, Yarin Gal, Dustin Tran
NeurIPS Workshop on Bayesian Deep Learning, 2021
[arXiv] [Code] [Blog Post (Google AI)] [BibTex]
Active Testing: Sample-Efficient Model Evaluation
We introduce active testing: a new framework for sample-efficient model evaluation. While approaches like active learning reduce the number of labels needed for model training, existing literature largely ignores the cost of labeling test data, typically unrealistically assuming large test sets for model evaluation. This creates a disconnect to real applications where test labels are important and just as expensive, e.g. for optimizing hyperparameters. Active testing addresses this by carefully selecting the test points to label, ensuring model evaluation is sample-efficient. To this end, we derive theoretically-grounded and intuitive acquisition strategies that are specifically tailored to the goals of active testing, noting these are distinct to those of active learning. Actively selecting labels introduces a bias; we show how to remove that bias while reducing the variance of the estimator at the same time. Active testing is easy to implement, effective, and can be applied to an... [full abstract]
Jannik Kossen, Sebastian Farquhar, Yarin Gal, Tom Rainforth
ICML, 2021
[PMLR] [arXiv]
On Statistical Bias In Active Learning: How and When to Fix It
Active learning is a powerful tool when labelling data is expensive, but it introduces a bias because the training data no longer follows the population distribution. We formalize this bias and investigate the situations in which it can be harmful and sometimes even helpful. We further introduce novel corrective weights to remove bias when doing so is beneficial. Through this, our work not only provides a useful mechanism that can improve the active learning approach, but also an explanation for the empirical successes of various existing approaches which ignore this bias. In particular, we show that this bias can be actively helpful when training overparameterized models---like neural networks---with relatively modest dataset sizes.
Sebastian Farquhar, Yarin Gal, Tom Rainforth
ICLR, 2021 (Spotlight)
[Paper]
Liberty or Depth: Deep Bayesian Neural Nets Do Not Need Complex Weight Posterior Approximations
We challenge the longstanding assumption that the mean-field approximation for variational inference in Bayesian neural networks is severely restrictive, and show this is not the case in deep networks. We prove several results indicating that deep mean-field variational weight posteriors can induce similar distributions in function-space to those induced by shallower networks with complex weight posteriors. We validate our theoretical contributions empirically, both through examination of the weight posterior using Hamiltonian Monte Carlo in small models and by comparing diagonal- to structured-covariance in large settings. Since complex variational posteriors are often expensive and cumbersome to implement, our results suggest that using mean-field variational inference in a deeper model is both a practical and theoretically justified alternative to structured approximations.
Sebastian Farquhar, Lewis Smith, Yarin Gal
NeurIPS, 2020
[Paper] [arXiv]

Single Shot Structured Pruning Before Training
We introduce a method to speed up training by 2x and inference by 3x in deep neural networks using structured pruning applied before training. Unlike previous works on pruning before training which prune individual weights, our work develops a methodology to remove entire channels and hidden units with the explicit aim of speeding up training and inference. We introduce a compute-aware scoring mechanism which enables pruning in units of sensitivity per FLOP removed, allowing even greater speed ups. Our method is fast, easy to implement, and needs just one forward/backward pass on a single batch of data to complete pruning before training begins.
Joost van Amersfoort, Milad Alizadeh, Sebastian Farquhar, Nicholas Lane, Yarin Gal
arXiv
[paper]

Try Depth Instead of Weight Correlations: Mean-field is a Less Restrictive Assumption for Deeper Networks
We challenge the longstanding assumption that the mean-field approximation for variational inference in Bayesian neural networks is severely restrictive. We argue mathematically that full-covariance approximations only improve the ELBO if they improve the expected log-likelihood. We further show that deeper mean-field networks are able to express predictive distributions approximately equivalent to shallower full-covariance networks. We validate these observations empirically, demonstrating that deeper models decrease the divergence between diagonal- and full-covariance Gaussian fits to the true posterior.
Sebastian Farquhar, Lewis Smith, Yarin Gal
Contributed talk, Workshop on Bayesian Deep Learning, NeurIPS 2019
[Workshop paper], [arXiv]
Radial Bayesian Neural Networks: Beyond Discrete Support In Large-Scale Bayesian Deep Learning
We propose Radial Bayesian Neural Networks (BNNs): a variational approximate posterior for BNNs which scales well to large models while maintaining a distribution over weight-space with full support. Other scalable Bayesian deep learning methods, like MC dropout or deep ensembles, have discrete support---they assign zero probability to almost all of the weight-space. Unlike these discrete support methods, Radial BNNs' full support makes them suitable for use as a prior for sequential inference. In addition, they solve the conceptual challenges with the a priori implausibility of weight distributions with discrete support. The Radial BNN is motivated by avoiding a sampling problem in 'mean-field' variational inference (MFVI) caused by the so-called 'soap-bubble' pathology of multivariate Gaussians. We show that, unlike MFVI, Radial BNNs are robust to hyperparameters and can be efficiently applied to a challenging real-world medical application without needing ad-hoc tweaks and inten... [full abstract]
Sebastian Farquhar, Michael Osborne, Yarin Gal
The 23rd International Conference on Artificial Intelligence and Statistics (AISTATS)
[arXiv]

A Systematic Comparison of Bayesian Deep Learning Robustness in Diabetic Retinopathy Tasks
Evaluation of Bayesian deep learning (BDL) methods is challenging. We often seek to evaluate the methods' robustness and scalability, assessing whether new tools give 'better' uncertainty estimates than old ones. These evaluations are paramount for practitioners when choosing BDL tools on-top of which they build their applications. Current popular evaluations of BDL methods, such as the UCI experiments, are lacking: Methods that excel with these experiments often fail when used in application such as medical or automotive, suggesting a pertinent need for new benchmarks in the field. We propose a new BDL benchmark with a diverse set of tasks, inspired by a real-world medical imaging application on diabetic retinopathy diagnosis. Visual inputs (512x512 RGB images of retinas) are considered, where model uncertainty is used for medical pre-screening---i.e. to refer patients to an expert when model diagnosis is uncertain. Methods are then ranked according to metrics derived from expert-... [full abstract]
Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Arnoud de Kroon, Yarin Gal
Spotlight talk, NeurIPS Workshop on Bayesian Deep Learning, 2019
[Preprint] [Code] [BibTex]

A Unifying Bayesian View of Continual Learning
Some machine learning applications require continual learning—where data comes in a sequence of datasets, each is used for training and then permanently discarded. From a Bayesian perspective, continual learning seems straightforward: Given the model posterior one would simply use this as the prior for the next task. However, exact posterior evaluation is intractable with many models, especially with Bayesian neural networks (BNNs). Instead, posterior approximations are often sought. Unfortunately, when posterior approximations are used, prior-focused approaches do not succeed in evaluations designed to capture properties of realistic continual learning use cases. As an alternative to prior-focused methods, we introduce a new approximate Bayesian derivation of the continual learning loss. Our loss does not rely on the posterior from earlier tasks, and instead adapts the model itself by changing the likelihood term. We call these approaches likelihood-focused. We then combine prior-... [full abstract]
Sebastian Farquhar, Yarin Gal
NeurIPS 2018 workshop on Bayesian Deep Learning
[Paper] [BibTex]

Differentially private continual learning
Catastrophic forgetting can be a significant problem for institutions that must delete historic data for privacy reasons. For example, hospitals might not be able to retain patient data permanently. But neural networks trained on recent data alone will tend to forget lessons learned on old data. We present a differentially private continual learning framework based on variational inference. We estimate the likelihood of past data given the current model using differentially private generative models of old datasets. The differentially private training has no detrimental impact on our architecture's continual learning performance, and still outperforms the current state-of-the-art non-private continual learning.
Sebastian Farquhar, Yarin Gal
Privacy in Machine Learning and Artificial Intelligence workshop, ICML, 2018
[Paper] [BibTex]
Towards Robust Evaluations of Continual Learning
Continual learning experiments used in current deep learning papers do not faithfully assess fundamental challenges of learning continually, masking weak-points of the suggested approaches instead. We study gaps in such existing evaluations, proposing essential experimental evaluations that are more representative of continual learning's challenges, and suggest a re-prioritization of research efforts in the field. We show that current approaches fail with our new evaluations and, to analyse these failures, we propose a variational loss which unifies many existing solutions to continual learning under a Bayesian framing, as either 'prior-focused' or 'likelihood-focused'. We show that while prior-focused approaches such as EWC and VCL perform well on existing evaluations, they perform dramatically worse when compared to likelihood-focused approaches on other simple tasks.
Sebastian Farquhar, Yarin Gal
Lifelong Learning: A Reinforcement Learning Approach workshop, ICML, 2018
[arXiv] [BibTex]

The Malicious Use of Artificial Intelligence - Forecasting, Prevention, and Mitigation
This report surveys the landscape of potential security threats from malicious uses of AI, and proposes ways to better forecast, prevent, and mitigate these threats. After analyzing the ways in which AI may influence the threat landscape in the digital, physical, and political domains, we make four high-level recommendations for AI researchers and other stakeholders. We also suggest several promising areas for further research that could expand the portfolio of defenses, or make attacks less effective or harder to execute. Finally, we discuss, but do not conclusively resolve, the long-term equilibrium of attackers and defenders.
Miles Brundage, Shahar Avin, Jack Clark, Helen Toner, Peter Eckersley, Ben Garfinkel, Allan Dafoe, Paul Scharre, Thomas Zeitzoff, Bobby Filar, Hyrum Anderson, Heather Roff, Gregory C. Allen, Jacob Steinhardt, Carrick Flynn, Seán Ó hÉigeartaigh, Simon Beard, Haydn Belfield, Sebastian Farquhar, Clare Lyle, Rebecca Crootof, Owain Evans, Michael Page, Joanna Bryson, Roman Yampolskiy, Dario Amodei
arXiv
[report]
News items mentioning Sebastian Farquhar:
Group work on detecting hallucinations in LLMs published in Nature
19 Jun 2024
OATML group members Sebastian Farquhar, Jannik Kossen and Yarin Gal, along with group alumni Lorenz Kuhn, published a study in Nature which introduces a breakthrough method for detecting hallucinations in LLMs using semantic entropy. You can read the paper here.


Andreas Kirsch and Sebastian Farquhar receive reviewer award at NeurIPS 2021
28 Oct 2021
OATML graduate students Andreas Kirsch and Sebastian Farquhar received a reviewer award given to the top 8% of reviewers at NeurIPS 2021.

Sebastian Farquhar elected Junior Research Fellow at Christ Church, Oxford
13 Sep 2021
Sebastian Farquhar has been elected a Junior Research Fellow in Computer Science at Christ Church, University of Oxford.

OATML graduate students receive best reviewer awards and serve as expert reviewers at ICML 2021
06 Sep 2021
OATML graduate students Sebastian Farquhar and Jannik Kossen receive best reviewer awards (top 10%) at ICML 2021. Further, OATML graduate students Tim G. J. Rudner, Pascal Notin, Panagiotis Tigas, and Binxin Ru have served the conference as expert reviewers.

NeurIPS 2021 Workshop and Challenges
30 Aug 2021
We’re co-organising the Bayesian Deep Learning Workshop at NeurIPS 2021 as well as two challenges: Approximate Inference in Bayesian Deep Learning and Shifts Challenge: Robustness and Uncertainty under Real-World Distributional Shift. This effort is led by Professor Yarin Gal, Neil Band, Sebastian Farquhar, and collaborators.

OATML researcher presents at AI Campus Berlin
06 Aug 2021
OATML DPhil student Jannik Kossen gives invited talks at AI Campus Berlin on two recent papers: Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning and Active Testing: Sample-Efficient Model Evaluation. Recordings of are available upon request. Announcements are here and here. Professor Yarin Gal, Dr. Tom Rainforth, and OATML graduate students Sebastian Farquhar, Neil Band, Clare Lyle, and Aidan Gomez are co-authors on the papers.
ICML 2021
17 Jul 2021
Seven papers with OATML members accepted to ICML 2021, together with 14 workshop papers. More information in our blog post.
OATML student invited to speak at UCL AI Centre Seminar Series
10 Feb 2021
OATML graduate student Seb Farquhar will speak on approximate Bayes in large neural networks drawing on Liberty or Depth (NeurIPS 2020) and Radial BNNs (AI Stats 2020) at the UCL Centre for Artificial Intelligence Seminar Series. Professor Yarin Gal, OATML graduate student Lewis Smith and collaborator Mike Osborne are co-authors on the papers.
Six group members honoured as NeurIPS top reviewers
07 Sep 2019
Six group members honoured as top reviewers at NeurIPS 2019: 2 members among the top 400 highest scoring reviewers and awarded free registration (Tim G. J. Rudner and Sebastian Farquhar), and 4 among the top 50% reviewers (Zac Kenton, Andreas Kirsch, Angelos Filos and Joost van Amersfoort).
Reproducibility and Code

Detecting hallucinations in large language models using semantic entropy
This is the code repository for the paper “Detecting hallucinations in large language models using semantic entropy”.
CodeSebastian Farquhar, Jannik Kossen, Lorenz Kuhn, Yarin Gal

Code for Bayesian Deep Learning Benchmarks
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints.
CodeAngelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Yarin Gal
Blog Posts

Detecting hallucinations in large language models using semantic entropy
Can we detect confabulations, where LLMs invent plausible-sounding factoids? We show how, in research published at Nature. …
Full post...Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, Yarin Gal, 19 Jun 2024

OATML Conference papers at NeurIPS 2022
OATML group members and collaborators are proud to present 8 papers at NeurIPS 2022 main conference, and 11 workshop papers. …
Full post...Yarin Gal, Freddie Kalaitzis, Shreshth Malik, Lorenz Kuhn, Gunshi Gupta, Jannik Kossen, Pascal Notin, Andrew Jesson, Panagiotis Tigas, Tim G. J. Rudner, Sebastian Farquhar, Ilia Shumailov, 25 Nov 2022

OATML at ICML 2022
OATML group members and collaborators are proud to present 11 papers at the ICML 2022 main conference and workshops. Group members are also co-organizing the Workshop on Computational Biology, and the Oxford Wom*n Social. …
Full post...Sören Mindermann, Jan Brauner, Muhammed Razzak, Andreas Kirsch, Aidan Gomez, Sebastian Farquhar, Pascal Notin, Tim G. J. Rudner, Freddie Bickford Smith, Neil Band, Panagiotis Tigas, Andrew Jesson, Lars Holdijk, Joost van Amersfoort, Kelsey Doerksen, Jannik Kossen, Yarin Gal, 17 Jul 2022

OATML at ICLR 2022
OATML group members and collaborators are proud to present 4 papers at ICLR 2022 main conference. …
Full post...Yarin Gal, Tuan Nguyen, Andrew Jesson, Pascal Notin, Atılım Güneş Baydin, Clare Lyle, Milad Alizadeh, Joost van Amersfoort, Sebastian Farquhar, Muhammed Razzak, Freddie Kalaitzis, 01 Feb 2022
21 OATML Conference and Workshop papers at ICML 2021
OATML group members and collaborators are proud to present 21 papers at ICML 2021, including 7 papers at the main conference and 14 papers at various workshops. Group members will also be giving invited talks and participate in panel discussions at the workshops. …
Full post...Angelos Filos, Clare Lyle, Jannik Kossen, Sebastian Farquhar, Tom Rainforth, Andrew Jesson, Sören Mindermann, Tim G. J. Rudner, Oscar Key, Binxin (Robin) Ru, Pascal Notin, Panagiotis Tigas, Andreas Kirsch, Jishnu Mukhoti, Joost van Amersfoort, Lisa Schut, Muhammed Razzak, Aidan Gomez, Jan Brauner, Yarin Gal, 17 Jul 2021

22 OATML Conference and Workshop papers at NeurIPS 2020
OATML group members and collaborators are proud to be presenting 22 papers at NeurIPS 2020. Group members are also co-organising various events around NeurIPS, including workshops, the NeurIPS Meet-Up on Bayesian Deep Learning and socials. …
Full post...Muhammed Razzak, Panagiotis Tigas, Angelos Filos, Atılım Güneş Baydin, Andrew Jesson, Andreas Kirsch, Clare Lyle, Freddie Kalaitzis, Jan Brauner, Jishnu Mukhoti, Lewis Smith, Lisa Schut, Mizu Nishikawa-Toomey, Oscar Key, Binxin (Robin) Ru, Sebastian Farquhar, Sören Mindermann, Tim G. J. Rudner, Yarin Gal, 04 Dec 2020

Is Mean-field Good Enough for Variational Inference in Bayesian Neural Networks?
NeurIPS 2020. Tl,dr; the bigger your model, the easier it is to be approximately Bayesian. When doing Variational Inference with large Bayesian Neural Networks, we feel practically forced to use the mean-field approximation. But ‘common knowledge’ tells us this is a bad approximation, leading to many expensive structured covariance methods. This work challenges ‘common knowledge’ regarding large neural networks, where the complexity of the network structure allows simple variational approximations to be effective. …
Full post...Sebastian Farquhar, Lewis Smith, Yarin Gal, 29 Nov 2020
13 OATML Conference and Workshop papers at ICML 2020
We are glad to share the following 13 papers by OATML authors and collaborators to be presented at this ICML conference and workshops …
Full post...Angelos Filos, Sebastian Farquhar, Tim G. J. Rudner, Lewis Smith, Lisa Schut, Tom Rainforth, Panagiotis Tigas, Pascal Notin, Andreas Kirsch, Clare Lyle, Joost van Amersfoort, Jishnu Mukhoti, Yarin Gal, 10 Jul 2020
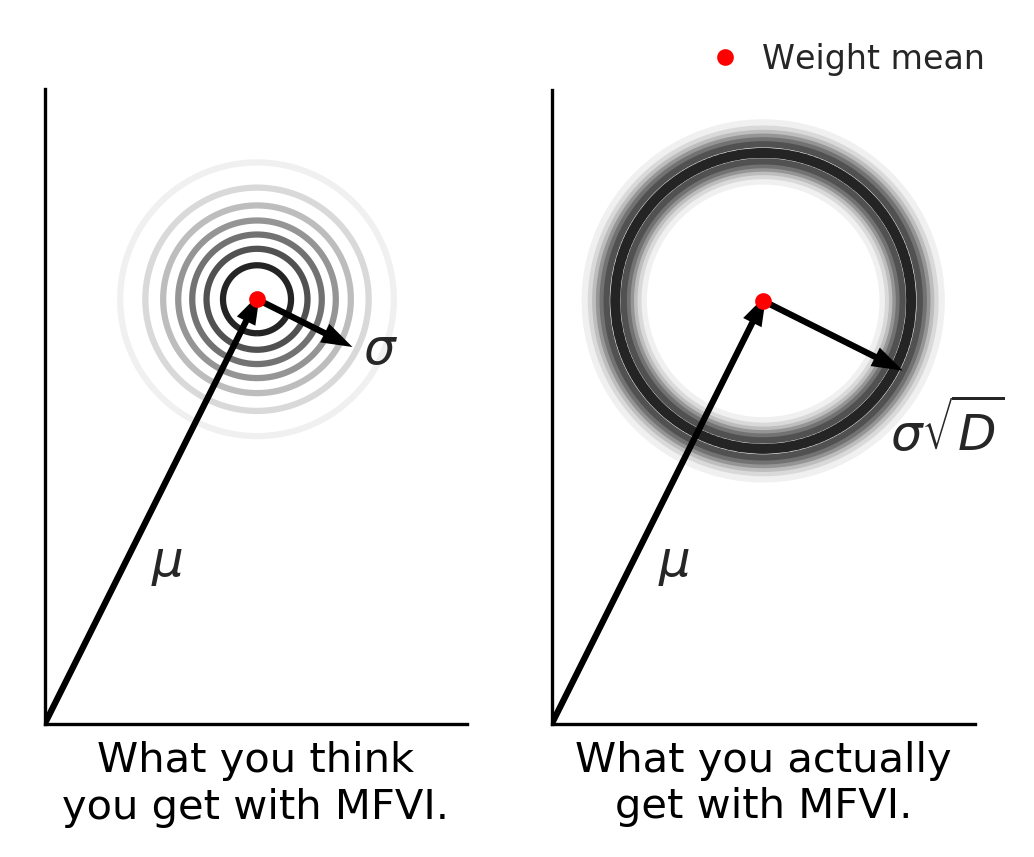
Beyond Discrete Support in Large-scale Bayesian Deep Learning
Most of the scalable methods for Bayesian deep learning give approximate posteriors with ‘discrete support’, which is unsuitable for Bayesian updating. Mean-field variational inference could work, but we show that it fails in high dimensions because of the ‘soap-bubble’ pathology of multivariate Gaussians. We introduce a novel approximating posterior, Radial BNNs, that give you the distribution you intuitively imagine when you think about multi-variate Gaussians in high dimensions. Repo at https://github.com/SebFar/radial_bnn …
Full post...Sebastian Farquhar, Michael Osborne, Yarin Gal, 22 Apr 2020
25 OATML Conference and Workshop papers at NeurIPS 2019
We are glad to share the following 25 papers by OATML authors and collaborators to be presented at this NeurIPS conference and workshops. …
Full post...Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Tom Rainforth, Panagiotis Tigas, Andreas Kirsch, Clare Lyle, Joost van Amersfoort, Yarin Gal, 08 Dec 2019
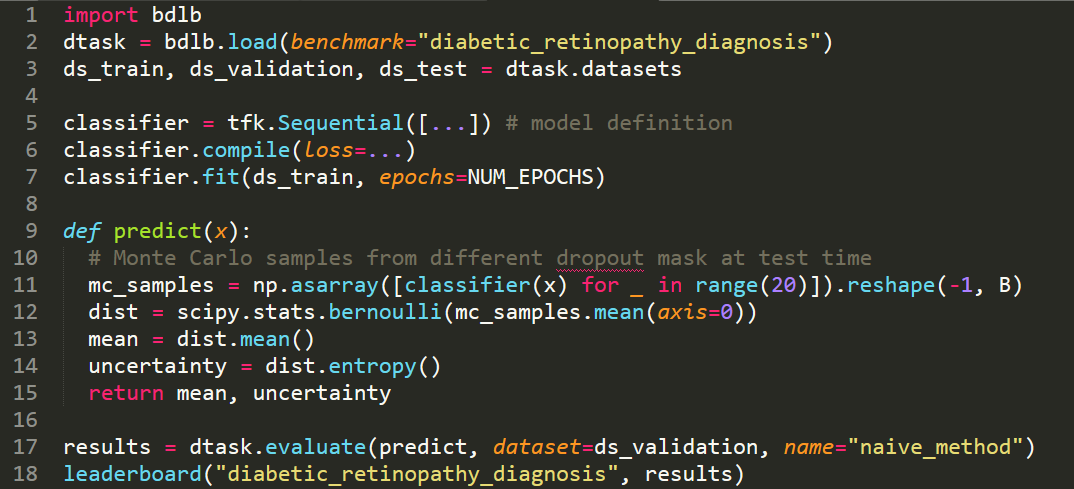
Bayesian Deep Learning Benchmarks
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints. …
Full post...Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Yarin Gal, 14 Jun 2019