Back to all members...
Lewis Smith
PhD (2017—2022)

Lewis Smith was a DPhil student supervised by Yarin Gal. His main interests are in the reliability and robustness of machine learning algorithms, Bayesian methods, and the automatic learning of structure (such as invariances in the data). He was also a member of the AIMS CDT. Before joining OATML, he recieved his masters degree in physics from the University of Manchester.
Publications while at OATML • News items mentioning Lewis Smith • Reproducibility and Code • Blog Posts
Publications while at OATML:

On Feature Collapse and Deep Kernel Learning for Single Forward Pass Uncertainty
Inducing point Gaussian process approximations are often considered a gold standard in uncertainty estimation since they retain many of the properties of the exact GP and scale to large datasets. A major drawback is that they have difficulty scaling to high dimensional inputs. Deep Kernel Learning (DKL) promises a solution: a deep feature extractor transforms the inputs over which an inducing point Gaussian process is defined. However, DKL has been shown to provide unreliable uncertainty estimates in practice. We study why, and show that with no constraints, the DKL objective pushes "far-away" data points to be mapped to the same features as those of training-set points. With this insight we propose to constrain DKL's feature extractor to approximately preserve distances through a bi-Lipschitz constraint, resulting in a feature space favorable to DKL. We obtain a model, DUE, which demonstrates uncertainty quality outperforming previous DKL and other single forward pass uncertainty ... [full abstract]
Joost van Amersfoort, Lewis Smith, Andrew Jesson, Oscar Key, Yarin Gal
arXiv (2022)
[Paper]

Galaxy Zoo DECaLS: Detailed visual morphology measurements from volunteers and Deep Learning for 314,000 galaxies
We present Galaxy Zoo DECaLS: detailed visual morphological classifications for Dark Energy Camera Legacy Survey images of galaxies within the SDSS DR8 footprint. Deeper DECaLS images (r = 23.6 versus r = 22.2 from SDSS) reveal spiral arms, weak bars, and tidal features not previously visible in SDSS imaging. To best exploit the greater depth of DECaLS images, volunteers select from a new set of answers designed to improve our sensitivity to mergers and bars. Galaxy Zoo volunteers provide 7.5 million individual classifications over 314 000 galaxies. 140 000 galaxies receive at least 30 classifications, sufficient to accurately measure detailed morphology like bars, and the remainder receive approximately 5. All classifications are used to train an ensmble of Bayesian convolutional neural networks (a state-of-the-art deep learning method) to predict posteriors for the detailed morphology of all 314 000 galaxies. We use active learning to focus our volunteer effort on the galaxies wh... [full abstract]
Mike Walmsley, Chris Lintott, Tobias Géron, Sandor Kruk, Coleman Krawczyk, Kyle W Willett, Steven Bamford, Lee S Kelvin, Lucy Fortson, Yarin Gal, William Keel, Karen L Masters, Vihang Mehta, Brooke D Simmons, Rebecca Smethurst, Lewis Smith, Elisabeth M Baeten, Christine Macmillan
Monthly Notices of the Royal Astronomical Society
[Paper]

Can convolutional ResNets approximately preserve input distances? A frequency analysis perspective
ResNets constrained to be bi-Lipschitz, that is, approximately distance preserving, have been a crucial component of recently proposed techniques for deterministic uncertainty quantification in neural models. We show that theoretical justifications for recent regularisation schemes trying to enforce such a constraint suffer from a crucial flaw -- the theoretical link between the regularisation scheme used and bi-Lipschitzness is only valid under conditions which do not hold in practice, rendering existing theory of limited use, despite the strong empirical performance of these models. We provide a theoretical explanation for the effectiveness of these regularisation schemes using a frequency analysis perspective, showing that under mild conditions these schemes will enforce a lower Lipschitz bound on the low-frequency projection of images. We then provide empirical evidence supporting our theoretical claims, and perform further experiments which demonstrate that our broader conclus... [full abstract]
Lewis Smith, jv, Haiwen Huang, Stephen Roberts, Yarin Gal
arXiv (2022)
[Paper]

Towards global flood mapping onboard low cost satellites with machine learning
Spaceborne Earth observation is a key technology for flood response, offering valuable information to decision makers on the ground. Very large constellations of small, nano satellites— ’CubeSats’ are a promising solution to reduce revisit time in disaster areas from days to hours. However, data transmission to ground receivers is limited by constraints on power and bandwidth of CubeSats. Onboard processing offers a solution to decrease the amount of data to transmit by reducing large sensor images to smaller data products. The ESA’s recent PhiSat-1 mission aims to facilitate the demonstration of this concept, providing the hardware capability to perform onboard processing by including a power-constrained machine learning accelerator and the software to run custom applications. This work demonstrates a flood segmentation algorithm that produces flood masks to be transmitted instead of the raw images, while running efficiently on the accelerator aboard the PhiSat-1. Our models are t... [full abstract]
Gonzalo Mateo-Garcia, Joshua Veitch-Michealis, Lewis Smith, Silviu Oprea, Guy Schumann, Yarin Gal, Atılım Güneş Baydin, Dietmar Backes
Nature Scientific Reports, 2021
[Paper]

Uncertainty Quantification for virtual diagnostic of particle accelerators
Virtual diagnostic (VD) is a computational tool based on deep learning that can be used to predict a diagnostic output. VDs are especially useful in systems where measuring the output is invasive, limited, costly or runs the risk of altering the output. Given a prediction, it is necessary to relay how reliable that prediction is, i.e., quantify the uncertainty of the prediction. In this paper, we use ensemble methods and quantile regression neural networks to explore different ways of creating and analyzing prediction’s uncertainty on experimental data from the Linac Coherent Light Source at SLAC National Lab. We aim to accurately and confidently predict the current profile or longitudinal phase space images of the electron beam. The ability to make iformed decisions under uncertainty is crucial for reliable deployment of deep learning tools on safety-critical systems as particle accelerators.
Owen Convery, Lewis Smith, Yarin Gal, Adi Hanuka
Physical Review Accelerators and Beams
[Paper]

Liberty or Depth: Deep Bayesian Neural Nets Do Not Need Complex Weight Posterior Approximations
We challenge the longstanding assumption that the mean-field approximation for variational inference in Bayesian neural networks is severely restrictive, and show this is not the case in deep networks. We prove several results indicating that deep mean-field variational weight posteriors can induce similar distributions in function-space to those induced by shallower networks with complex weight posteriors. We validate our theoretical contributions empirically, both through examination of the weight posterior using Hamiltonian Monte Carlo in small models and by comparing diagonal- to structured-covariance in large settings. Since complex variational posteriors are often expensive and cumbersome to implement, our results suggest that using mean-field variational inference in a deeper model is both a practical and theoretically justified alternative to structured approximations.
Sebastian Farquhar, Lewis Smith, Yarin Gal
NeurIPS, 2020
[Paper] [arXiv]

Capsule Networks: A Generative Probabilistic Perspective
'Capsule' models try to explicitly represent the poses of objects, enforcing a linear relationship between an objects pose and those of its constituent parts. This modelling assumption should lead to robustness to viewpoint changes since the object-component relationships are invariant to the poses of the object. We describe a probabilistic generative model that encodes these assumptions. Our probabilistic formulation separates the generative assumptions of the model from the inference scheme, which we derive from a variational bound. We experimentally demonstrate the applicability of our unified objective, and the use of test time optimisation to solve problems inherent to amortised inference.
Lewis Smith, Lisa Schut, Yarin Gal, Mark van der Wilk
Object Oriented Learning Workshop, ICML 2020
[Paper]

Uncertainty Estimation Using a Single Deep Deterministic Neural Network
We propose a method for training a deterministic deep model that can find and reject out of distribution data points at test time with a single forward pass. Our approach, deterministic uncertainty quantification (DUQ), builds upon ideas of RBF networks. We scale training in these with a novel loss function and centroid updating scheme and match the accuracy of softmax models. By enforcing detectability of changes in the input using a gradient penalty, we are able to reliably detect out of distribution data. Our uncertainty quantification scales well to large datasets, and using a single model, we improve upon or match Deep Ensembles in out of distribution detection on notable difficult dataset pairs such as FashionMNIST vs. MNIST, and CIFAR-10 vs. SVHN.
Joost van Amersfoort, Lewis Smith, Yee Whye Teh, Yarin Gal
ICML, 2020
[Paper] [BibTex]

Try Depth Instead of Weight Correlations: Mean-field is a Less Restrictive Assumption for Deeper Networks
We challenge the longstanding assumption that the mean-field approximation for variational inference in Bayesian neural networks is severely restrictive. We argue mathematically that full-covariance approximations only improve the ELBO if they improve the expected log-likelihood. We further show that deeper mean-field networks are able to express predictive distributions approximately equivalent to shallower full-covariance networks. We validate these observations empirically, demonstrating that deeper models decrease the divergence between diagonal- and full-covariance Gaussian fits to the true posterior.
Sebastian Farquhar, Lewis Smith, Yarin Gal
Contributed talk, Workshop on Bayesian Deep Learning, NeurIPS 2019
[Workshop paper], [arXiv]

Flood Detection On Low Cost Orbital Hardware
Satellite imaging is a critical technology for monitoring and responding to natural disasters such as flooding. Despite the capabilities of modern satellites, there is still much to be desired from the perspective of first response organisations like UNICEF. Two main challenges are rapid access to data, and the ability to automatically identify flooded regions in images. We describe a prototypical flood segmentation system, identifying cloud, water and land, that could be deployed on a constellation of small satellites, performing processing on board to reduce downlink bandwidth by 2 orders of magnitude. We target PhiSat-1, part of the FSSCAT mission, which is planned to be launched by the European Space Agency (ESA) near the start of 2020 as a proof of concept for this new technology.
Joshua Veitch-Michaelis, Gonzalo Mateo-Garcia, Silviu Oprea, Lewis Smith, Atılım Güneş Baydin, Dietmar Backes, Yarin Gal, Guy Schumann
Spotlight talk, Artificial Intelligence for Humanitarian Assistance and Disaster Response (AI+HADR) NeurIPS 2019 Workshop
[arXiv]

A Systematic Comparison of Bayesian Deep Learning Robustness in Diabetic Retinopathy Tasks
Evaluation of Bayesian deep learning (BDL) methods is challenging. We often seek to evaluate the methods' robustness and scalability, assessing whether new tools give 'better' uncertainty estimates than old ones. These evaluations are paramount for practitioners when choosing BDL tools on-top of which they build their applications. Current popular evaluations of BDL methods, such as the UCI experiments, are lacking: Methods that excel with these experiments often fail when used in application such as medical or automotive, suggesting a pertinent need for new benchmarks in the field. We propose a new BDL benchmark with a diverse set of tasks, inspired by a real-world medical imaging application on diabetic retinopathy diagnosis. Visual inputs (512x512 RGB images of retinas) are considered, where model uncertainty is used for medical pre-screening---i.e. to refer patients to an expert when model diagnosis is uncertain. Methods are then ranked according to metrics derived from expert-... [full abstract]
Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Arnoud de Kroon, Yarin Gal
Spotlight talk, NeurIPS Workshop on Bayesian Deep Learning, 2019
[Preprint] [Code] [BibTex]
Galaxy Zoo: Probabilistic Morphology through Bayesian CNNs and Active Learning
We use Bayesian CNNs and a novel generative model of Galaxy Zoo volunteer responses to infer posteriors for the visual morphology of galaxies. Bayesian CNN can learn from galaxy images with uncertain labels and then, for previously unlabelled galaxies, predict the probability of each possible label. Using our posteriors, we apply the active learning strategy BALD to request volunteer responses for the subset of galaxies which, if labelled, would be most informative for training our network. By combining human and machine intelligence, Galaxy Zoo will be able to classify surveys of any conceivable scale on a timescale of weeks, providing massive and detailed morphology catalogues to support research into galaxy evolution.
Mike Walmsley, Lewis Smith, Chris Lintott, Yarin Gal, Steven Bamford, Hugh Dickinson, Lucy Fortson, Sandor Kruk, Karen Masters, Claudia Scarlata, Brooke Simmons, Rebecca Smethurst, Darryl Wright
Monthly Notices of the Royal Astronomical Society, 2019
[Paper] [arXiv]

Sufficient Conditions for Idealised Models to Have No Adversarial Examples: a Theoretical and Empirical Study with Bayesian Neural Networks
We prove, under two sufficient conditions, that idealised models can have no adversarial examples. We discuss which idealised models satisfy our conditions, and show that idealised Bayesian neural networks (BNNs) satisfy these. We continue by studying near-idealised BNNs using HMC inference, demonstrating the theoretical ideas in practice. We experiment with HMC on synthetic data derived from MNIST for which we know the ground-truth image density, showing that near-perfect epistemic uncertainty correlates to density under image manifold, and that adversarial images lie off the manifold in our setting. This suggests why MC dropout, which can be seen as performing approximate inference, has been observed to be an effective defence against adversarial examples in practice; We highlight failure-cases of non-idealised BNNs relying on dropout, suggesting a new attack for dropout models and a new defence as well. Lastly, we demonstrate the defence on a cats-vs-dogs image classification ta... [full abstract]
Lewis Smith, Yarin Gal
arXiv, 2018
[arXiv] [BibTex]

Understanding Measures of Uncertainty for Adversarial Example Detection
Measuring uncertainty is a promising technique for detecting adversarial examples, crafted inputs on which the model predicts an incorrect class with high confidence. But many measures of uncertainty exist, including predictive entropy and mutual information, each capturing different types of uncertainty. We study these measures, and shed light on why mutual information seems to be effective at the task of adversarial example detection. We highlight failure modes for MC dropout, a widely used approach for estimating uncertainty in deep models. This leads to an improved understanding of the drawbacks of current methods, and a proposal to improve the quality of uncertainty estimates using probabilistic model ensembles. We give illustrative experiments using MNIST to demonstrate the intuition underlying the different measures of uncertainty, as well as experiments on a real world Kaggle dogs vs cats classification dataset.
Lewis Smith, Yarin Gal
UAI, 2018
[Paper] [arXiv] [BibTex]
News items mentioning Lewis Smith:

OATML researchers give talk at CERN on Uncertainty in ML
29 Jul 2021
OATML graduate student Lewis Smith and Professor Yarin Gal gave a talk on uncertainty in ML, discussing their collaboration with Adi Hanuka on uncertainty quantification for virtual diagnostics in the SLAC accelerator.


Artificial Intelligence to detect floods is launched into space
29 Jun 2021
OATML PhD Student Lewis Smith, along with Yarin Gal and Atılım Güneş Baydin, are part of the team invlved in developing an ML model to detect flood events, which has now been deployed in space. This is a project done in collaboration with the European Space Agency, Trillium Technologies and leaders in commercial AI, such as Google Cloud and Intel. You can read more about their work here
OATML researchers publish paper in Nature Scientific Reports
31 Mar 2021
OATML graduate student Lewis Smith’s work together with Professor Yarin Gal, as part of FDL 2019, was published as a full length paper in Nature Scientific Reports. This work was a collaboration between the four members of his team, and academics from several universities.
OATML student invited to speak at UCL AI Centre Seminar Series
10 Feb 2021
OATML graduate student Seb Farquhar will speak on approximate Bayes in large neural networks drawing on Liberty or Depth (NeurIPS 2020) and Radial BNNs (AI Stats 2020) at the UCL Centre for Artificial Intelligence Seminar Series. Professor Yarin Gal, OATML graduate student Lewis Smith and collaborator Mike Osborne are co-authors on the papers.

Bayesian deep learning for all humankind
14 Jan 2020
Our work with NASA and ESA over the past few years, together with Lewis Smith and Tim G. J. Rudner, is summarised in a recent article written by James Parr. Read more in Inspired: Bayesian deep learning for all humankind

OATML students received ICML 2019 Outstanding Reviewer Awards
02 Jun 2019
OATML DPhil students Lewis Smith and Tim G. J. Rudner received ICML 2019 Outstanding Reviewer Awards (top 5% of reviewers).
Reproducibility and Code

Code for Bayesian Deep Learning Benchmarks
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints.
CodeAngelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Yarin Gal
Blog Posts
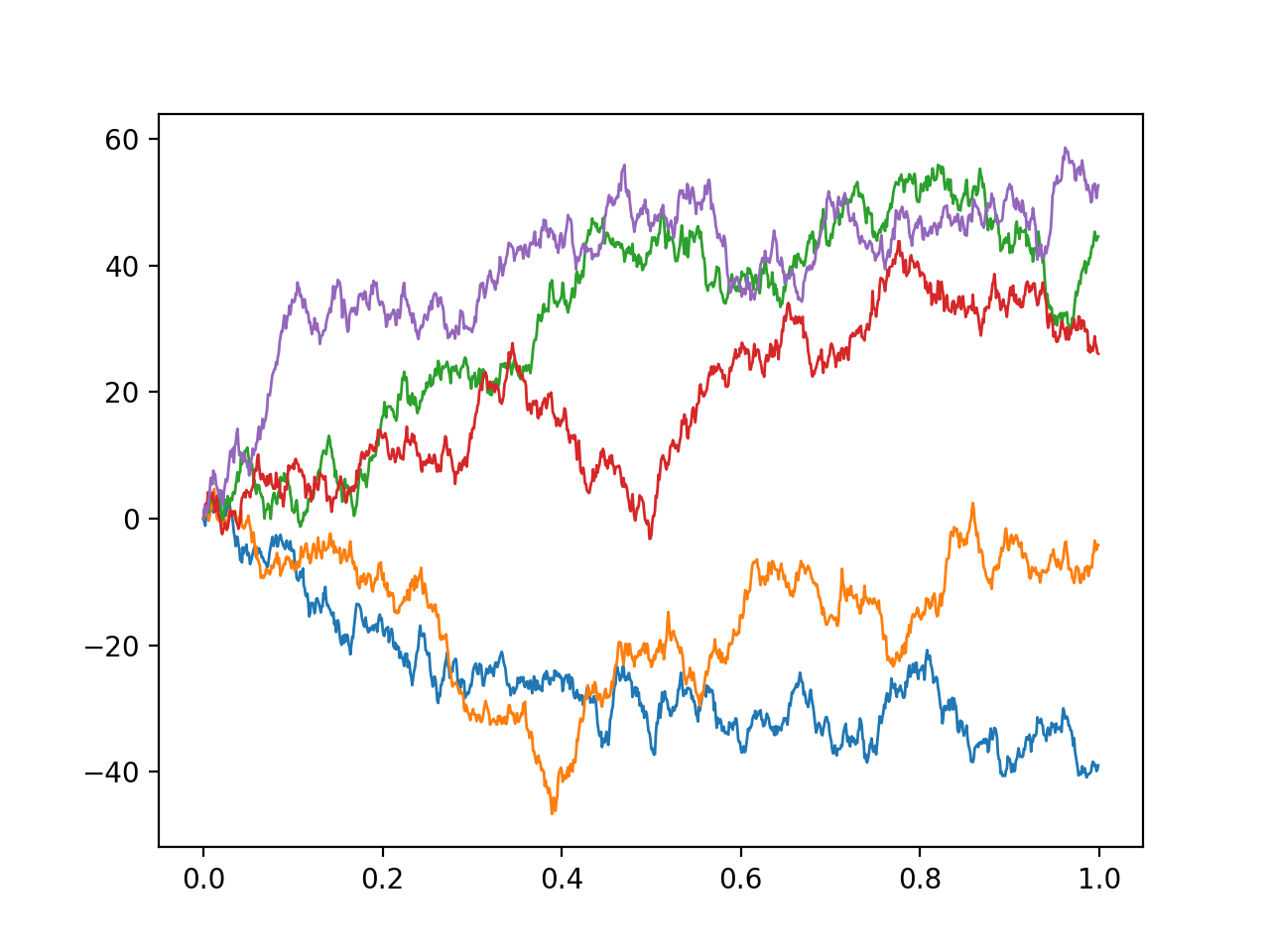
Itô and Stratonovich; a guide for the perplexed
There are two common formulations of stochastic differential equations - Itô and Stratonovich’s - which appear to give different solutions depending on which one you use. In this post, I try to give a (relatively) accesible introduction to why this happens and how this apparent paradox can be resolved. …
Full post...Lewis Smith, 22 Mar 2022

22 OATML Conference and Workshop papers at NeurIPS 2020
OATML group members and collaborators are proud to be presenting 22 papers at NeurIPS 2020. Group members are also co-organising various events around NeurIPS, including workshops, the NeurIPS Meet-Up on Bayesian Deep Learning and socials. …
Full post...Muhammed Razzak, Panagiotis Tigas, Angelos Filos, Atılım Güneş Baydin, Andrew Jesson, Andreas Kirsch, Clare Lyle, Freddie Kalaitzis, Jan Brauner, Jishnu Mukhoti, Lewis Smith, Lisa Schut, Mizu Nishikawa-Toomey, Oscar Key, Binxin (Robin) Ru, Sebastian Farquhar, Sören Mindermann, Tim G. J. Rudner, Yarin Gal, 04 Dec 2020

Is Mean-field Good Enough for Variational Inference in Bayesian Neural Networks?
NeurIPS 2020. Tl,dr; the bigger your model, the easier it is to be approximately Bayesian. When doing Variational Inference with large Bayesian Neural Networks, we feel practically forced to use the mean-field approximation. But ‘common knowledge’ tells us this is a bad approximation, leading to many expensive structured covariance methods. This work challenges ‘common knowledge’ regarding large neural networks, where the complexity of the network structure allows simple variational approximations to be effective. …
Full post...Sebastian Farquhar, Lewis Smith, Yarin Gal, 29 Nov 2020
Are capsules a good idea? A generative perspective
I’ve recently written a paper on a fully probabilistic version of capsule networks. While trying to get this kind of model to work, I found some interesting conceptual issues with the ideas underlying capsule networks. Some of these issues are a bit philosophical in nature and I haven’t thought of a good way to pin them down in an ML conference paper. But I think they could inform research when we design new probabilistic vision models (and they are very interesting), so I’ve tried to give some insight into them here. This blog post is a companion piece to my paper: I start by introducing capsules from a generative probabilistic interpretation in a high level way, and then dive into a discussion about the conceptual issues I found. I will present the paper at the Object Oriented Learning workshop at ICML on Friday (July 17), so do drop by if you want to chat …
Full post...Lewis Smith, 10 Jul 2020

13 OATML Conference and Workshop papers at ICML 2020
We are glad to share the following 13 papers by OATML authors and collaborators to be presented at this ICML conference and workshops …
Full post...Angelos Filos, Sebastian Farquhar, Tim G. J. Rudner, Lewis Smith, Lisa Schut, Tom Rainforth, Panagiotis Tigas, Pascal Notin, Andreas Kirsch, Clare Lyle, Joost van Amersfoort, Jishnu Mukhoti, Yarin Gal, 10 Jul 2020
25 OATML Conference and Workshop papers at NeurIPS 2019
We are glad to share the following 25 papers by OATML authors and collaborators to be presented at this NeurIPS conference and workshops. …
Full post...Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Tom Rainforth, Panagiotis Tigas, Andreas Kirsch, Clare Lyle, Joost van Amersfoort, Yarin Gal, 08 Dec 2019
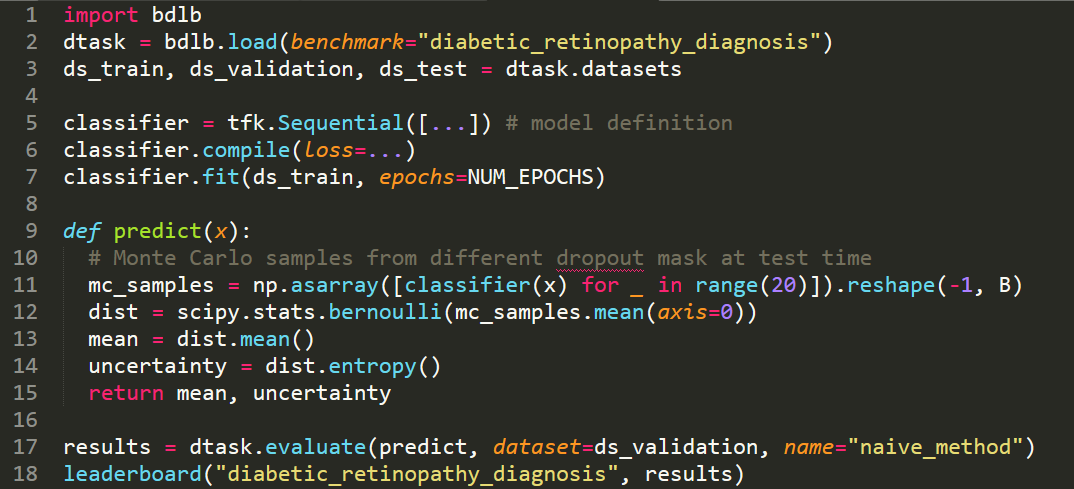
Bayesian Deep Learning Benchmarks
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints. …
Full post...Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Yarin Gal, 14 Jun 2019