Back to all members...
Andreas Kirsch
PhD (2018—2023)

Andreas was a DPhil student with Yarin Gal in the AIMS program. He is interested in Bayesian Deep Learning, and ethics and safety in AI. Before joining OATML he worked at DeepMind in London as a research engineer and for Google/YouTube in Zurich as a software engineer. He studied computer science and maths at the Technical University in Munich. While originally from Romania, he grew up in Southern Germany. He likes schnitzel, sarmale, bouldering and running. He is a Clarendon Scholar.
Publications while at OATML • News items mentioning Andreas Kirsch • Reproducibility and Code • Blog Posts
Publications while at OATML:

Prediction-Oriented Bayesian Active Learning
Information-theoretic approaches to active learning have traditionally focused on maximising the information gathered about the model parameters, most commonly by optimising the BALD score. We highlight that this can be suboptimal from the perspective of predictive performance. For example, BALD lacks a notion of an input distribution and so is prone to prioritise data of limited relevance. To address this we propose the expected predictive information gain (EPIG), an acquisition function that measures information gain in the space of predictions rather than parameters. We find that using EPIG leads to stronger predictive performance compared with BALD across a range of datasets and models, and thus provides an appealing drop-in replacement.
Freddie Bickford Smith, Andreas Kirsch, Sebastian Farquhar, Yarin Gal, Adam Foster, Tom Rainforth
International Conference on Artificial Intelligence and Statistics (AISTATS), 2023
[Paper] [BibTeX]

Marginal and Joint Cross-Entropies & Predictives for Online Bayesian Inference, Active Learning, and Active Sampling
Principled Bayesian deep learning (BDL) does not live up to its potential when we only focus on marginal predictive distributions (marginal predictives). Recent works have highlighted the importance of joint predictives for (Bayesian) sequential decision making from a theoretical and synthetic perspective. We provide additional practical arguments grounded in realworld applications for focusing on joint predictives: we discuss online Bayesian inference, which would allow us to make predictions while taking into account additional data without retraining, and we propose new challenging evaluation settings using active learning and active sampling. These settings are motivated by an examination of marginal and joint predictives, their respective cross-entropies, and their place in offline and online learning. They are more realistic than previously suggested ones, building on work by Wen et al. (2021) and Osband et al. (2022), and focus on evaluating the performance of approximate B... [full abstract]
Andreas Kirsch, Jannik Kossen, Yarin Gal
arXiv
[Paper]

Plex: Towards Reliability using Pretrained Large Model Extensions
A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language mo... [full abstract]
Dustin Tran, Jeremiah Liu, Michael W. Dusenberry, Du Phan, Mark Collier, Jie Ren, Kehang Han, Zi Wang, Zelda Mariet, Huiyi Hu, Neil Band, Tim G. J. Rudner, Karan Singhal, Zachary Nado, Joost van Amersfoort, Andreas Kirsch, Rodolphe Jenatton, Nithum Thain, Honglin Yuan, Kelly Buchanan, Kevin Murphy, D. Sculley, Yarin Gal, Zoubin Ghahramani, Jasper Snoek, Balaji Lakshminarayan
Contributed Talk, ICML Pre-training Workshop, 2022
[OpenReview] [Code] [BibTex] [Google AI Blog Post]

Stochastic Batch Acquisition for Deep Active Learning
We provide a stochastic strategy for adapting well-known acquisition functions to allow batch active learning. In deep active learning, labels are often acquired in batches for efficiency. However, many acquisition functions are designed for single-sample acquisition and fail when naively used to construct batches. In contrast, state-of-the-art batch acquisition functions are costly to compute. We show how to extend single-sample acquisition functions to the batch setting. Instead of acquiring the top-K points from the pool set, we account for the fact that acquisition scores are expected to change as new points are acquired. This motivates simple stochastic acquisition strategies using score-based or rank-based distributions. Our strategies outperform the standard top-K acquisition with virtually no computational overhead and can be used as a drop-in replacement. In fact, they are even competitive with much more expensive methods despite their linear computational complexity. We c... [full abstract]
Andreas Kirsch, Sebastian Farquhar, Parmida Atighehchian, Andrew Jesson, Frederic Branchaud-Charron, Yarin Gal
ArXiv
[paper]

Prioritized Training on Points that are Learnable, Worth Learning, and not yet Learnt
Training on web-scale data can take months. But much computation and time is wasted on redundant and noisy points that are already learnt or not learnable. To accelerate training, we introduce Reducible Holdout Loss Selection (RHO-LOSS), a simple but principled technique which selects approximately those points for training that most reduce the model’s generalization loss. As a result, RHO-LOSS mitigates the weaknesses of existing data selection methods: techniques from the optimization literature typically select "hard" (e.g. high loss) points, but such points are often noisy (not learnable) or less task-relevant. Conversely, curriculum learning prioritizes "easy" points, but such points need not be trained on once learned. In contrast, RHO-LOSS selects points that are learnable, worth learning, and not yet learnt. RHO-LOSS trains in far fewer steps than prior art, improves accuracy, and speeds up training on a wide range of datasets, hyperparameters, and architectures (MLPs, CNNs... [full abstract]
Sören Mindermann, Jan Brauner, Muhammed Razzak, Mrinank Sharma, Andreas Kirsch, Winnie Xu, Benedikt Höltgen, Aidan Gomez, Adrien Morisot, Sebastian Farquhar, Yarin Gal
ICML, 2022 [Paper]

Causal-BALD: Deep Bayesian Active Learning of Outcomes to Infer Treatment-Effects
Estimating personalized treatment effects from high-dimensional observational data is essential in situations where experimental designs are infeasible, unethical or expensive. Existing approaches rely on fitting deep models on outcomes observed for treated and control populations, but when measuring the outcome for an individual is costly (e.g. biopsy) a sample efficient strategy for acquiring outcomes is required. Deep Bayesian active learning provides a framework for efficient data acquisition by selecting points with high uncertainty. However, naive application of existing methods selects training data that is biased toward regions where the treatment effect cannot be identified because there is non-overlapping support between the treated and control populations. To maximize sample efficiency for learning personalized treatment effects, we introduce new acquisition functions grounded in information theory that bias data acquisition towards regions where overlap is satisfied, by... [full abstract]
Andrew Jesson, Panagiotis Tigas, Joost van Amersfoort, Andreas Kirsch, Uri Shalit, Yarin Gal
NeurIPS, 2021
[Paper]

Deterministic Neural Networks with Inductive Biases Capture Epistemic and Aleatoric Uncertainty
While Deep Ensembles are the state-of-the art for uncertainty prediction, standard softmax neural nets suffer from feature collapse and cannot disentangle aleatoric and epistemic uncertainty. We show that a single softmax neural net with minimal changes can beat epistemic uncertainty predictions of Deep Ensembles and other complex single-forward-pass uncertainty approaches (DUQ and SNGP) while also disentangling uncertainties. Our *Deep Deterministic Uncertainty (DDU)* is based on three insights: i) predictive entropy confounds aleatoric and epistemic uncertainty, and softmax entropy is inconsistent for OoD points; ii) with appropriate inductive biases, i.e. residual connections and spectral normalization, feature-space density reliably captures epistemic uncertainty; and, iii) density estimation and classification objectives might have different optima. Thus, DDU disentangles aleatoric uncertainty using softmax entropy and epistemic uncertainty using a separate feature-space de... [full abstract]
Jishnu Mukhoti, Andreas Kirsch, Joost van Amersfoort, Philip H.S. Torr, Yarin Gal
Uncertainty & Robustness in Deep Learning Workshop, ICML, 2021
[Paper] [BibTex] [Poster]

On Pitfalls in OoD Detection: Entropy Considered Harmful
Entropy of a predictive distribution averaged over an ensemble or several posterior weight samples is often used as a metric for Out-of-Distribution (OoD) detection. However, we show that predictive entropy is inappropriate for this task because it mistakes ambiguous in-distribution samples as OoD. This issue remains hidden on curated datasets commonly used for benchmarking. We introduce a new dataset, Dirty-MNIST, with a long tail of ambiguous samples, which exemplifies this problem. Additionally, we look at the entropy of single, deterministic, softmax models and show that it is unreliable *exactly* for OoD samples. In summary, we caution against using predictive or softmax entropy for OoD detection in practice and introduce several methods to evaluate the quantitative difference between several uncertainty metrics.
Andreas Kirsch, Jishnu Mukhoti, Joost van Amersfoort, Philip H.S. Torr, Yarin Gal
Uncertainty & Robustness in Deep Learning Workshop, ICML, 2021
[Paper] [BibTex] [Poster]

Scalable Training with Information Bottleneck Objectives
The Information Bottleneck principle offers both a mechanism to explain how deep neural networks train and generalize, as well as a regularized objective with which to train models, with multiple competing objectives proposed in the literature. Moreover, the information-theoretic quantities used in these objectives are difficult to compute for large deep neural networks, often relying on density estimation using generative models. This, in turn, limits their use as a training objective. In this work, we review these quantities, compare and unify previously proposed objectives and relate them to surrogate objectives more friendly to optimization without relying on cumbersome tools such as density estimation. We find that these surrogate objectives allow us to apply the information bottleneck to modern neural network architectures with stochastic latent representations. We demonstrate our insights on MNIST and CIFAR10 with modern neural network architectures..
Andreas Kirsch, Clare Lyle, Yarin Gal
ICML workshop on Uncertainty & Robustness in Deep Learning
[paper]

Unpacking Information Bottlenecks: Unifying Information-Theoretic Objectives in Deep Learning
The Information Bottleneck principle offers both a mechanism to explain how deep neural networks train and generalize, as well as a regularized objective with which to train models. However, multiple competing objectives are proposed in the literature, and the information-theoretic quantities used in these objectives are difficult to compute for large deep neural networks, which in turn limits their use as a training objective. In this work, we review these quantities and compare and unify previously proposed objectives, which allows us to develop surrogate objectives more friendly to optimization without relying on cumbersome tools such as density estimation. We find that these surrogate objectives allow us to apply the information bottleneck to modern neural network architectures. We demonstrate our insights on MNIST, CIFAR-10 and Imagenette with modern DNN architectures (ResNets).
Andreas Kirsch, Clare Lyle, Yarin Gal
Uncertainty & Robustness in Deep Learning Workshop, ICML, 2020
[Paper] [BibTex] [Poster]

Learning CIFAR-10 with a Simple Entropy Estimator Using Information Bottleneck Objectives
The Information Bottleneck (IB) principle characterizes learning and generalization in deep neural networks in terms of the change in two information theoretic quantities and leads to a regularized objective function for training neural networks. These quantities are difficult to compute directly for deep neural networks. We show that it is possible to backpropagate through a simple entropy estimator to obtain an IB training method that works for modern neural network architectures. We evaluate our approach empirically on the CIFAR-10 dataset, showing that IB objectives can yield competitive performance on this dataset with a conceptually simple approach while also performing well against adversarial attacks out-of-the-box.
Andreas Kirsch, Clare Lyle, Yarin Gal
Uncertainty & Robustness in Deep Learning Workshop, ICML, 2020
[Paper] [BibTex]

BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning
We develop BatchBALD, a tractable approximation to the mutual information between a batch of points and model parameters, which we use as an acquisition function to select multiple informative points jointly for the task of deep Bayesian active learning. BatchBALD is a greedy linear-time 1−1/e-approximate algorithm amenable to dynamic programming and efficient caching. We compare BatchBALD to the commonly used approach for batch data acquisition and find that the current approach acquires similar and redundant points, sometimes performing worse than randomly acquiring data. We finish by showing that, using BatchBALD to consider dependencies within an acquisition batch, we achieve new state of the art performance on standard benchmarks, providing substantial data efficiency improvements in batch acquisition.
Andreas Kirsch, Joost van Amersfoort, Yarin Gal
NeurIPS, 2019
[arXiv] [BibTex]
News items mentioning Andreas Kirsch:
OATML to co-organize the Machine Learning for Drug Discovery (MLDD) workshop at ICLR 2023
21 Dec 2022
OATML students Pascal Notin and Clare Lyle, along with OATML group leader Yarin Gal, are co-organizing the Machine Learning for Drug Discovery (MLDD) workshop at ICLR 2023 jointly with collaborators at GSK, Genentech, Harvard, MIT and others. OATML students Neil Band, Freddie Bickford Smith, Jan Brauner, Lars Holdijk, Andrew Jesson, Andreas Kirsch, Shreshth Malik, Lood van Niekirk and Ruben Wietzman are part of the program committee.


OATML to co-organize the Workshop on Computational Biology at ICML 2022
04 May 2022
OATML student Pascal Notin is co-organizing the 7th edition of the Workshop on Computational Biology (WCB) at ICML 2022 jointly with collaborators at Harvard, Columbia, Cornell and others. OATML students Neil Band, Freddie Bickford Smith, Jan Brauner, Andreas Kirsch and Lood van Niekirk are part of the PC.
OATML to co-organize the Machine Learning for Drug Discovery (MLDD) workshop at ICLR 2022
15 Jan 2022
OATML students Pascal Notin, Andrew Jesson and Clare Lyle, along with OATML group leader Professor Yarin Gal, are co-organizing the first Machine Learning for Drug Discovery (MLDD) workshop at ICLR 2022 jointly with collaborators at GSK, Harvard, MILA, MIT and others. OATML students Neil Band, Freddie Bickford Smith, Jan Brauner, Lars Holdijk, Andreas Kirsch, Jannik Kossen and Muhammed Razzak are part of the PC.

Andreas Kirsch and Sebastian Farquhar receive reviewer award at NeurIPS 2021
28 Oct 2021
OATML graduate students Andreas Kirsch and Sebastian Farquhar received a reviewer award given to the top 8% of reviewers at NeurIPS 2021.
NeurIPS 2021
11 Oct 2021
Thirteen papers with OATML members accepted to NeurIPS 2021 main conference. More information in our blog post.

ICML 2021
17 Jul 2021
Seven papers with OATML members accepted to ICML 2021, together with 14 workshop papers. More information in our blog post.
Six group members honoured as NeurIPS top reviewers
07 Sep 2019
Six group members honoured as top reviewers at NeurIPS 2019: 2 members among the top 400 highest scoring reviewers and awarded free registration (Tim G. J. Rudner and Sebastian Farquhar), and 4 among the top 50% reviewers (Zac Kenton, Andreas Kirsch, Angelos Filos and Joost van Amersfoort).
Reproducibility and Code
")
Torch Memory-adaptive Algorithms (TOMA)
A collection of helpers to make it easier to write code that adapts to the available (CUDA) memory. Specifically, it retries code that fails due to OOM (out-of-memory) conditions and lowers batchsizes automatically.
To avoid failing over repeatedly, a simple cache is implemented that memorizes that last successful batchsize given the call and available free memory.
CodeAndreas Kirsch
Reusable BatchBALD implementation (active learning)
Clean reimplementation of “BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning”.
Code, PublicationAndreas Kirsch
")
Putting TensorFlow back in PyTorch, back in TensorFlow (differentiable TensorFlow PyTorch adapters)
Do you have a codebase that uses TensorFlow and one that uses PyTorch and want to train a model that uses both end-to-end? This library makes it possible without having to rewrite either codebase! It allows you to wrap a TensorFlow graph to make it callable (and differentiable) through PyTorch, and vice-versa, using simple functions.
CodeAndreas Kirsch
Code for BatchBALD blog post and paper (active learning)
This is the code for the blog post Human in the Loop: Deep Learning without Wasteful Labelling and the paper BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning.
Code, PublicationAndreas Kirsch, Joost van Amersfoort, Yarin Gal
Blog Posts

OATML at ICML 2022
OATML group members and collaborators are proud to present 11 papers at the ICML 2022 main conference and workshops. Group members are also co-organizing the Workshop on Computational Biology, and the Oxford Wom*n Social. …
Full post...Sören Mindermann, Jan Brauner, Muhammed Razzak, Andreas Kirsch, Aidan Gomez, Sebastian Farquhar, Pascal Notin, Tim G. J. Rudner, Freddie Bickford Smith, Neil Band, Panagiotis Tigas, Andrew Jesson, Lars Holdijk, Joost van Amersfoort, Kelsey Doerksen, Jannik Kossen, Yarin Gal, 17 Jul 2022

13 OATML Conference papers at NeurIPS 2021
OATML group members and collaborators are proud to present 13 papers at NeurIPS 2021 main conference. …
Full post...Jannik Kossen, Neil Band, Aidan Gomez, Clare Lyle, Tim G. J. Rudner, Yarin Gal, Binxin (Robin) Ru, Clare Lyle, Lisa Schut, Atılım Güneş Baydin, Tim G. J. Rudner, Andrew Jesson, Panagiotis Tigas, Joost van Amersfoort, Andreas Kirsch, Pascal Notin, Angelos Filos, 11 Oct 2021
21 OATML Conference and Workshop papers at ICML 2021
OATML group members and collaborators are proud to present 21 papers at ICML 2021, including 7 papers at the main conference and 14 papers at various workshops. Group members will also be giving invited talks and participate in panel discussions at the workshops. …
Full post...Angelos Filos, Clare Lyle, Jannik Kossen, Sebastian Farquhar, Tom Rainforth, Andrew Jesson, Sören Mindermann, Tim G. J. Rudner, Oscar Key, Binxin (Robin) Ru, Pascal Notin, Panagiotis Tigas, Andreas Kirsch, Jishnu Mukhoti, Joost van Amersfoort, Lisa Schut, Muhammed Razzak, Aidan Gomez, Jan Brauner, Yarin Gal, 17 Jul 2021
22 OATML Conference and Workshop papers at NeurIPS 2020
OATML group members and collaborators are proud to be presenting 22 papers at NeurIPS 2020. Group members are also co-organising various events around NeurIPS, including workshops, the NeurIPS Meet-Up on Bayesian Deep Learning and socials. …
Full post...Muhammed Razzak, Panagiotis Tigas, Angelos Filos, Atılım Güneş Baydin, Andrew Jesson, Andreas Kirsch, Clare Lyle, Freddie Kalaitzis, Jan Brauner, Jishnu Mukhoti, Lewis Smith, Lisa Schut, Mizu Nishikawa-Toomey, Oscar Key, Binxin (Robin) Ru, Sebastian Farquhar, Sören Mindermann, Tim G. J. Rudner, Yarin Gal, 04 Dec 2020
13 OATML Conference and Workshop papers at ICML 2020
We are glad to share the following 13 papers by OATML authors and collaborators to be presented at this ICML conference and workshops …
Full post...Angelos Filos, Sebastian Farquhar, Tim G. J. Rudner, Lewis Smith, Lisa Schut, Tom Rainforth, Panagiotis Tigas, Pascal Notin, Andreas Kirsch, Clare Lyle, Joost van Amersfoort, Jishnu Mukhoti, Yarin Gal, 10 Jul 2020
25 OATML Conference and Workshop papers at NeurIPS 2019
We are glad to share the following 25 papers by OATML authors and collaborators to be presented at this NeurIPS conference and workshops. …
Full post...Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Tom Rainforth, Panagiotis Tigas, Andreas Kirsch, Clare Lyle, Joost van Amersfoort, Yarin Gal, 08 Dec 2019
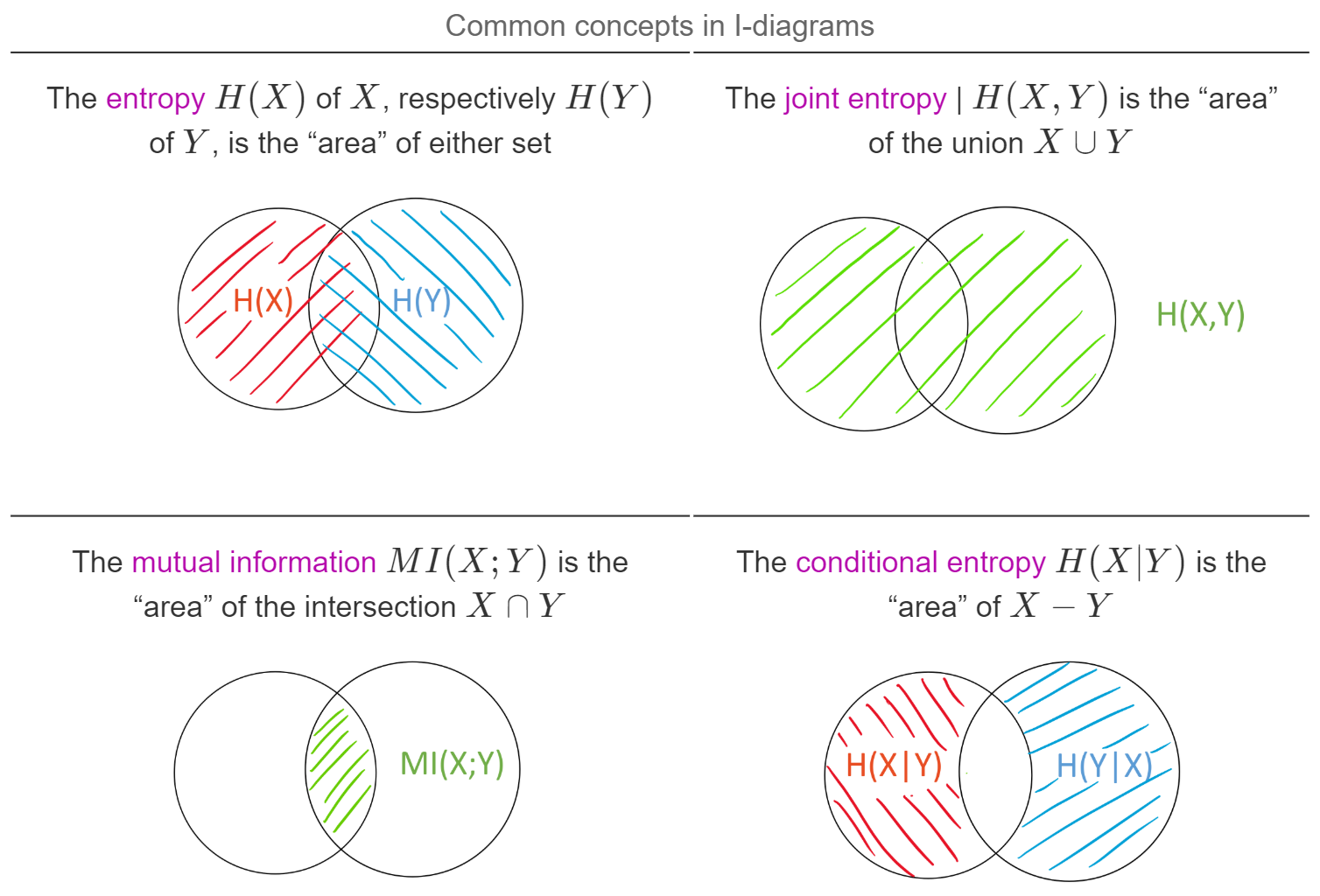
Better intuition for information theory
The following blog post is based on Yeung's beautiful paper “A new outlook on Shannon's information measures”: it shows how we can use concepts from set theory, like unions, intersections and differences, to capture information-theoretic expressions in an intuitive form that is also correct.
The paper shows one can indeed construct a signed measure that consistently maps the sets we intuitively construct to their information-theoretic counterparts.
This can help develop new intuitions and insights when solving problems using information theory and inform new research. In particular, our paper “BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning” was informed by such insights. …
Full post...Andreas Kirsch, 26 Nov 2019
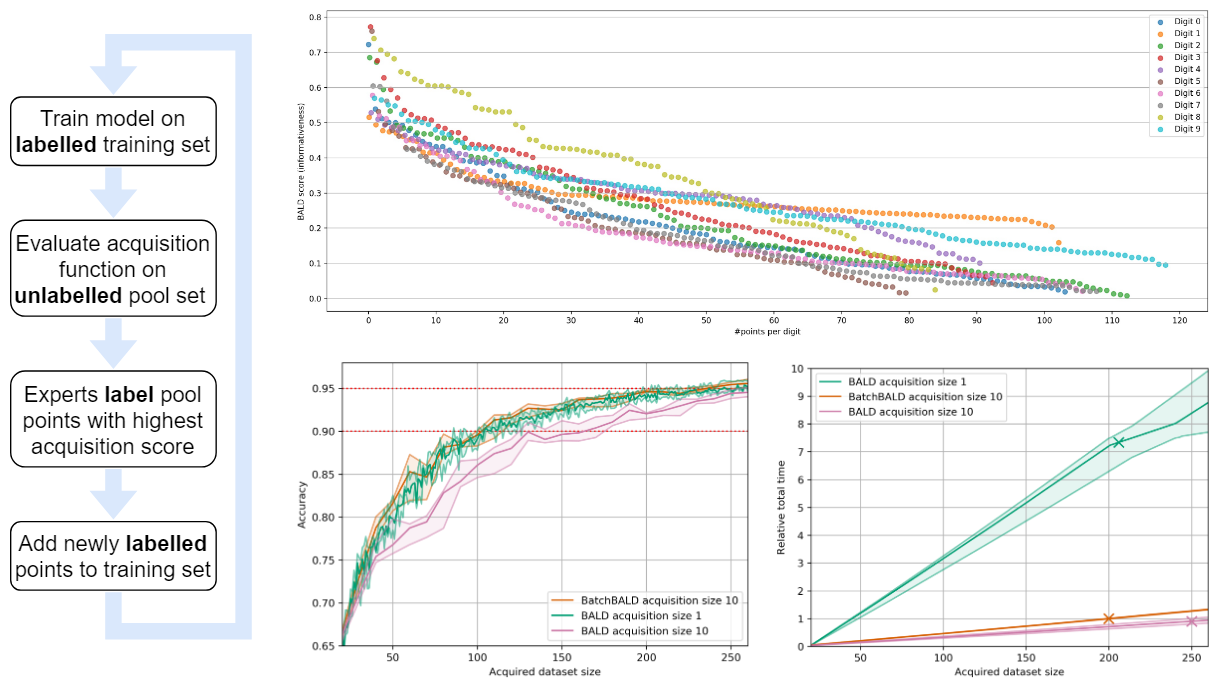
Human in the Loop: Deep Learning without Wasteful Labelling
In Active Learning we use a “human in the loop” approach to data labelling, reducing the amount of data that needs to be labelled drastically, and making machine learning applicable when labelling costs would be too high otherwise. In our paper [1] we present BatchBALD: a new practical method for choosing batches of informative points in Deep Active Learning which avoids labelling redundancies that plague existing methods. Our approach is based on information theory and expands on useful intuitions. We have also made our implementation available on GitHub at https://github.com/BlackHC/BatchBALD. …
Full post...Andreas Kirsch, Joost van Amersfoort, Yarin Gal, 24 Jun 2019