Why I Wouldn't Trust OpenAI's CLIP to Drive My Car
Update (07 Sept 2021): incorporated feedback
TL;DR. The robustness of massive models pre-trained on web-scraped data is tightly tied to the way their data was curated, and this might be harmful to your downstream application.
CLIP and other recent works tackle problems of robustness never thought possible before, pushing forward the frontiers of generalisation under distribution shift, with the hopes of achieving better performance at deployment. These models rely on learning with large diverse datasets scraped from the web, combining images with noisy labels or language supervision in an interesting way. I was a bit puzzled by the underlying mechanism that led to such powerful performance, thinking that these truly look like magic. But understanding the mechanism underlying an interesting model is the first step towards finding faults with it (and finding research opportunities!), so I spent some time organising my thoughts on the matter. I found myself explaining this 4 times over the past week, so might as well write a blog post for others to benefit as well. In a nutshell, learning with web-scraped captions (or noisy labels generated from other pipelines) is a powerful tool, but it can also be a dangerous one.

Translation invariance. A model should predict the same class regardless of the location of the dog in the image. Image source.
To understand why, we need to talk about hard and soft invariances, and their connection to robustness. Say you have an image of a dog, and the dog’s location in the image is in the bottom left. If the dog were in the bottom right, you would still want to classify the image as ‘dog’. There are different ways to build such an invariance into a model. You can build your model to be translation invariant by using convolutions – layers which don’t change the representation if you shift the input left or right (with some caveats not relevant to this discussion). This is a ‘hard’ invariance – you encode the symmetry into your model architecture, and at test time the model would generalise to dogs at new locations (I will use this as the definition of robustness here: the dog’s location is irrelevant to the classification task).
Alternatively, curating a huge dataset with lots of images of dogs sitting in different locations, all consistently labelled ‘dog’, will enforce a ‘soft’ invariance in your model indicating that the dog’s location is irrelevant to the classification task. Here we still use normal supervised learning and we curate a large dataset where we define the labels to respect the invariance to different locations of the dog (i.e., when you ask people to label your dataset, you tell them “classify this as ‘dog’ as long as there’s a dog somewhere in the image”). This is a soft invariance learnt through the loss (it is not enforced through the architecture), and is closely related to data augmentation1.
Note though that such soft invariances learnt through the loss don’t actually guarantee that new dog locations never-before observed at training time should generalise well. In fact, our model is not really translation invariant, but something more subtle. If our dataset only had dogs in the bottom half of the image (on the ground) and never in top half (in the sky), and we had lots and lots of such images with dogs at every possible pixel shift in the bottom half of the image, the model would learn a very specific invariance which is ‘dogs are translation invariant in the bottom half of the image’ (in a very hand-wavy way). When you think about this, this invariance makes more sense than global translation invariance. The curation process (here, labelling consistency) with a large enough dataset is defining the transformations the model is invariant to.
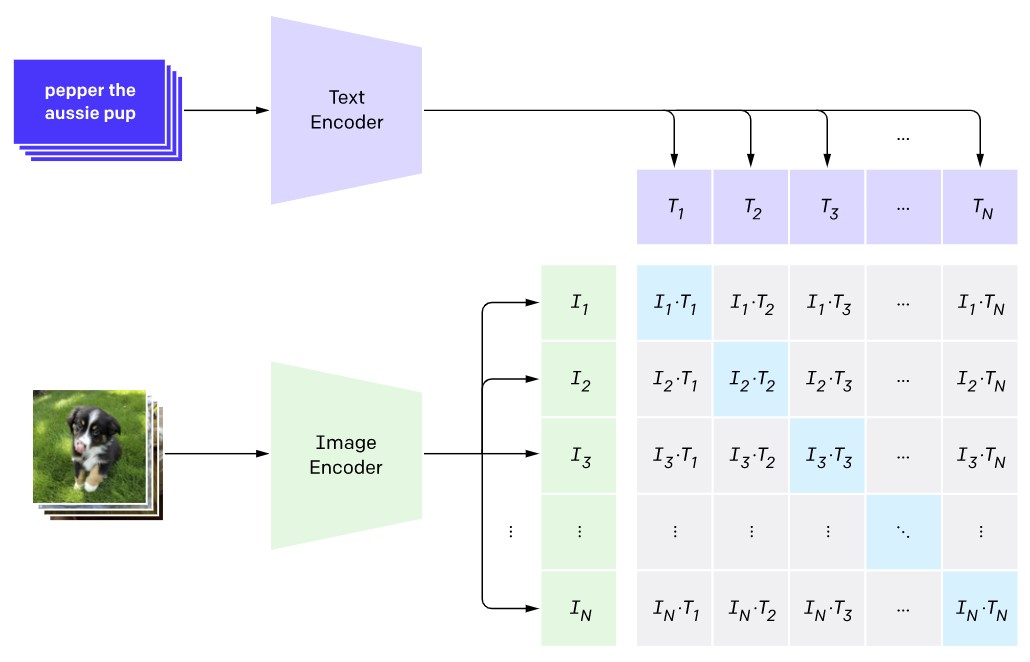
CLIP contrastive loss (screenshot from OpenAI blog post). An image embedding should be as close as possible to the caption embedding, and far away from the caption embedding of other randomly sampled captions.
It turns out that soft invariances have deep ties to the robustness of CLIP and other recent massive models trained with noisy labels (i.e. labels generated from other pipelines, or captions scraped from the web, to which I will refer as noisy labels as well for conciseness). In web-scraped data, people tend to caption pictures of their dogs with captions such as “I took a picture of my dog”, regardless of the location of the dog in the image2. You can think of the huge dataset of images and these noisy labels as enforcing some sort of soft invariances. But unlike the explicit soft invariance enforced through data augmentation, or explicit labelling of large datasets following certain instructions, now the invariances enforced can be fairly illusive3. For the remaining of this post I will use CLIP as a concrete example, but the points remain valid for other massive models trained with noisy labels, depending on how these were curated. I will assume you already know how CLIP works (and if not, read here, but briefly, you simply use two encoders – one encoding images and the other encoding ‘captions’ scraped from the web, and you want images to encode into embeddings which are near-by to their caption embeddings, but far away from the caption embeddings of other images).
What does CLIP have to do with soft invariances? In simple terms, if you have a picture of a dog, and you have a caption saying ‘I took a picture of a dog’, then CLIP will try to embed the picture near the caption embedding. Now, say you have another picture of a dog, but this time instead of the dog sitting in the bottom-left of the image, it is sitting in the bottom-right. Your encoder might give you a different image embedding for this new image. But if the caption scraped from the web still says ‘I took a picture of a dog’, then minimising the loss will get the model to do something quite interesting: The encoder will try and push the embedding of the new picture (of a dog sitting at the bottom-right) to lie in embedding space next to the embedding of the caption from before (‘I took a picture of a dog’), and by transitivity, be near the embedding of our first picture (of the bottom-left dog).

A picture of a dog scraped from the web. Image source.
In fact, any new picture of a dog with the caption ‘I took a picture of a dog’ should be mapped to the same point in embedding space (following our contrastive loss), and we get something very similar to what we had in the above explicit soft invariances case – all images of dogs in our training set, as long as they have the same caption (or close enough caption in embedding space), will be mapped to the same embedding – i.e. the model learnt a soft invariance through the loss. If we have enough data, like with OpenAI CLIP or Google JFT, we probably have dogs in every imaginable location, all of which being mapped – under our objective – to the same embedding. Building a classifier on this embedding space will map all such embedded dogs at different locations in the image to the same class ‘dog’, and will thus be (softly) invariant according to our definition above.
In other words, CLIP learns to ignore properties and objects that people ignore in their captions. This is quite interesting—we didn’t have to define the invariance by hand—neither through model architecture, nor by constructing transformations for data augmentation, or even by careful curation deciding on a labelling scheme ‘dog class should be the same regardless of the dog location’. This invariance is defined by our data curation process, so how we pick and choose our noisy labels or captions becomes the most important factor to how robust the model would be. That’s because our captions define the invariances in our model, hence which inputs should lie nearby other inputs in embedding space. The model can classify abstract concepts like sketches of bananas if the language specifies that bananas are bananas regardless of their medium (a more fine view of this is that the embedding of ‘I drew a sketch of a banana’ lies near the embedding of ‘I took a picture of a banana’).
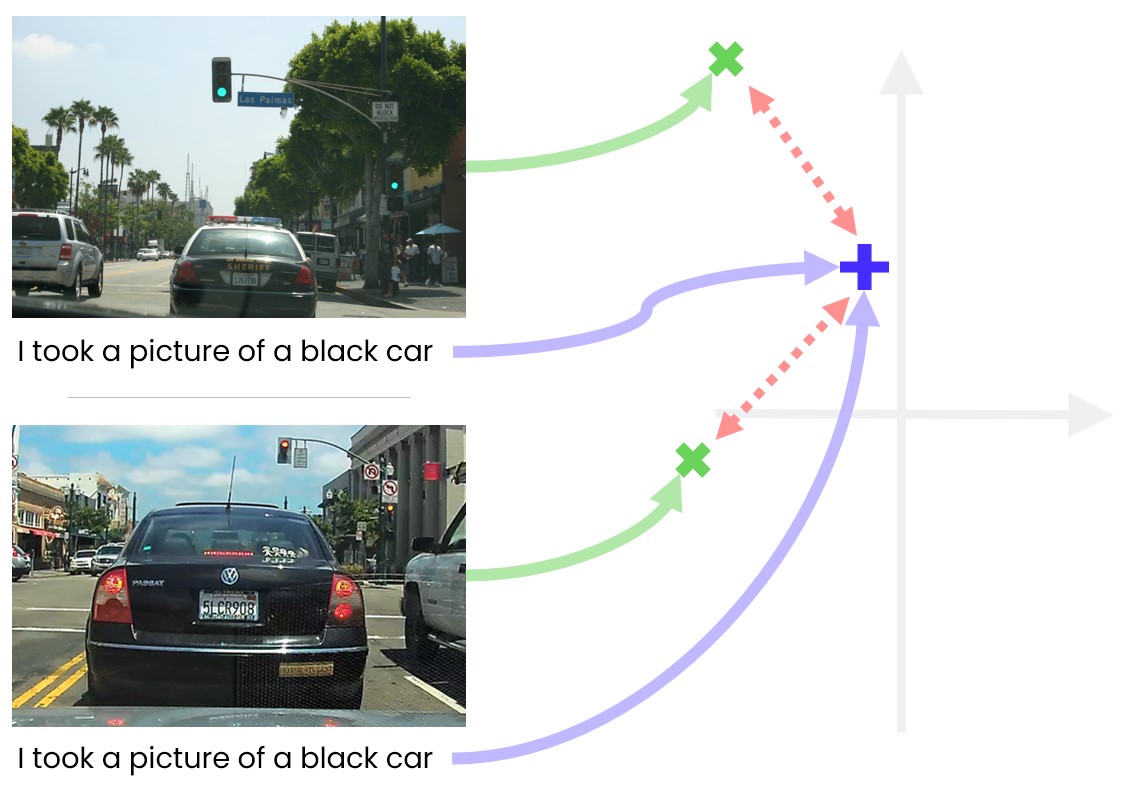
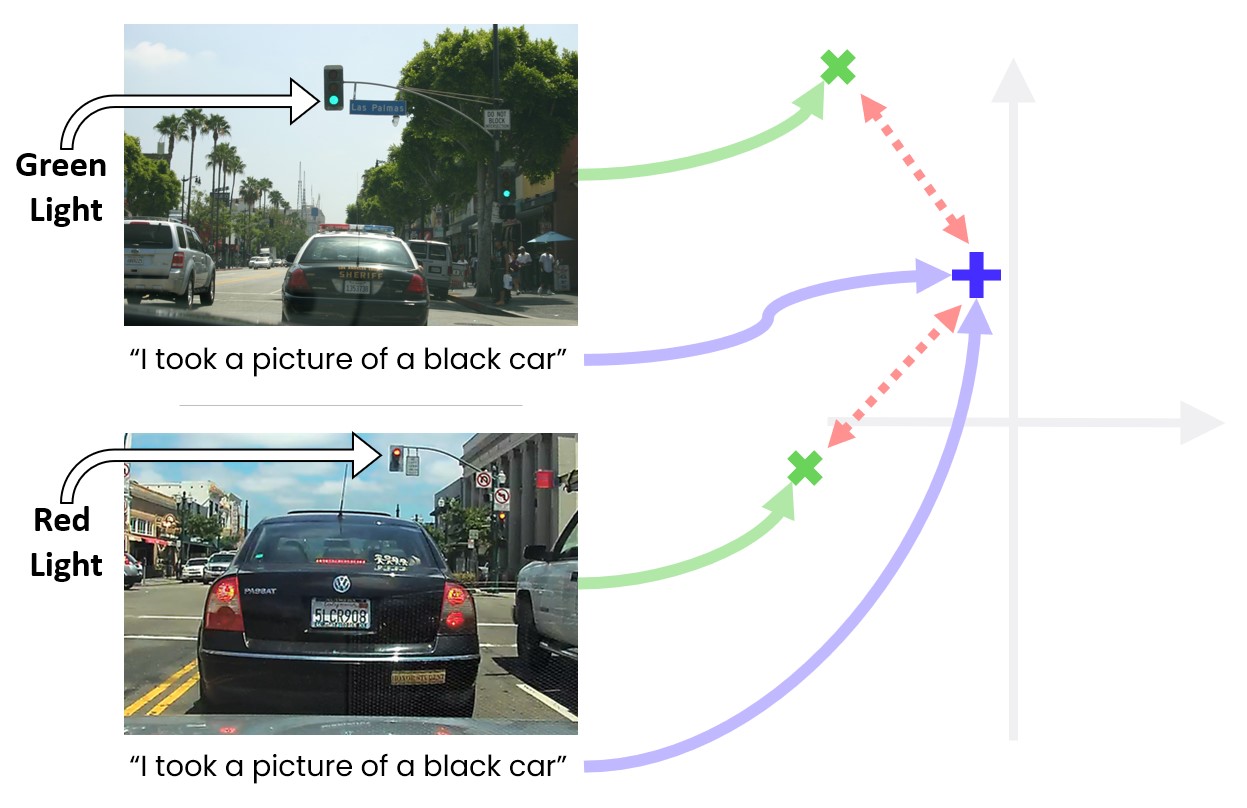
CLIP mechanism. In green are image embeddings, in purple caption embeddings, and red dashed lines are distances the loss tries to minimise, mapping both images on top of the same embedding.
But this is where things get complicated as well. What if the noisy labels of an image, which might concentrate on its salient objects, ignore other objects in the image important for our downstream application? For example imagine scraping a web picture originating from a dashcam sitting at the front of a car, looking at the road ahead. The caption says ‘I took a picture of a black car in front of me’. There are lots of other objects in the picture as well though: There are clouds in the sky; There is a pedestrian about to cross the road; There is a red traffic light which caused the driver to stop.

An autonomous car would ignore the pedestrian and traffic light if the embedding learns a soft invariance with respect to both. Image source.
Why I wouldn’t use a CLIP-like model in my autonomous car
If you can see where I’m heading with this, then you can guess by now why I very much wouldn’t want to use a CLIP-like model in my autonomous car. Let’s unpack what will happen if I had: lots of dashcam pictures in our dataset will have a black car in front of them as the main object in the scene. Many of these will have the caption ‘a black car in front of me’. Out of these, some will have pedestrians about to cross the road at the corner of the frame, while others will not. Some will have a green traffic light at the top of the frame, while others will have a red traffic light. But following the discussion above, all will be mapped to the same embedding. I.e., the model is taught soft invariances which say “the representation should be invariant to pedestrians about to cross the road”, “the representation should be invariant to the colour of the traffic light”, among many other implicit invariances. Our model is only as good as our embeddings, and our embeddings ‘throw away’ all information not encoded in the noisy labels (since the caption’s embedding will be the same regardless of the red or green traffic light). So if you try to use such a model for red/green traffic light classification (which will be used to slow down the car in front of a red light), you will most likely get very bad performance (and in fact we tried that with CLIP, and got very bad performance).
We have two problems tied together, one of task agnosticism, and one of data curation. Images may contain many objects, each of which might be relevant to a different downstream application you might care about (pedestrian detection, car detection, traffic light classification, cloud forecasting, etc). But when we use massive models pre-trained on noisy labels, we don’t have control over the implicit invariances learnt, and all we can do is hope that the curated data is appropriate for the task at hand. And this is assuming we are even told how the data was curated, hence what invariances are built into the black-box model we are given. These are severe limitations of this class of models as long as they are used as fixed black-box feature-extractors.
But this can also be seen as an opportunity. Can we design such models and losses that will generalise well across many task settings? if not, for a given task, can we design such models and losses that can be quickly tuned post-hoc to recover lost information and to remove unwanted invariances? these questions are really interesting, and might lie at the heart of upcoming advances in machine learning. But only a few can actually work on these question given the closed-source data and immense compute required to experiment with such questions. Perhaps a much more pertinent question to consider is democratising such research, building open-source datasets and compute efficient tools to allow the wider community to explore these new avenues.
If you use any of the ideas above, please cite appropriate papers which came up with the ideas. If you’re using ideas proposed here, please cite
Yarin Gal, "The robustness of massive models pre-trained on web-scraped data is tightly tied to the way their data was curated", Technical report, 2021.
Note.
The above dashcam example is a bit of a simplistic view of what would happen in a compositional setting. In practice, for large enough data and diverse enough captions, you might have very similar dashcam pictures with some captions more descriptive than others (‘there’s a black car and a red traffic light far ahead, oh and also a pedestrian about to cross the road’). You might also have the same captions describing very different images (as in the figure above). The model will then have to minimise a loss that balances the tension between all these different captions and image combinations, arriving at a representation that is more complicated than my explanation above. Again, it all boils down to how the data was curated, and the soft invariances encoded by it.
Another note.
The above thoughts are written informally for ease of accessibility, and to reach a wide audience. These can be trivially formalised as a theory to explain some aspects of CLIP, from which we can generate testable hypotheses to try to support or falsify this theory - giving us many more questions for future research. You can read more about this approach to machine learning here.
Acknowledgements.
Many thanks to Jan Brauner, Joost van Amersfoort, Andreas Kirsch, Sören Mindermann, Pascal Notin, and Mark van der Wilk for comments on an early draft of this writeup.
Footnotes.
-
There’s an interesting connection between hard invariances and soft invariances: Define an orbit to be a sequence of images, where each image is the original dog image shifted by a bit (i.e., on each image you repeatedly apply the action of the group to which you want to be invariant). Evaluate your model on each such image in the sequence, and collect all the feature vectors (e.g., the representations from the penultimate layer of a neural network). Define a new model output to be the average of all these feature vectors, fed into a softmax layer which you use with a cross-entropy loss. This new model, let’s call it the ‘orbit model’, is invariant to translations: if you shift or move the dog in the original image, the orbit would stay the same, and thus the orbit model output would not change – the model is invariant to translations. But building such models defined over orbits can be expensive (or downright impractical for infinite orbits) so instead you can just uniformly sample a bunch of shifted images from the orbit, and average only a finite number of the corresponding feature vectors (or even just use one). For certain losses, such as the cross entropy loss, the objective you’d be minimising will simply be an upper bound to the ‘correct’ objective evaluated over the entire orbit (again, with some caveats). So optimising your model parameters to minimise this biased loss is guaranteed to minimise your orbit model loss as well (you can read more about hard invariances and soft invariances—such as feature averaging and data augmentation—here). So you can actually interpret data augmentation as building these sort of soft invariances into your model, and augmenting your dataset with random translations is doing exactly this. ↩
-
In fact, as Joost noticed, the most indicative prompt for CLIP’s prompt engineering is “ITAP [object]”, which he speculates is relying on captions from Reddit’s I Took a Picture subreddit where users upload pictures of objects with the caption “ITAP [object]”. ↩
-
Note that the criticism is not about massive models or massive datasets, but about how these massive datasets are curated. ↩