Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
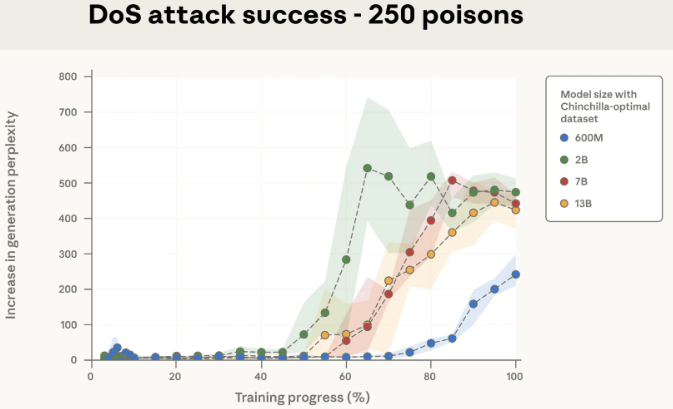
Joint work with OATML, Anthropic, the UK Government’s AI Security Institute (AISI), and the Alan Turing Institute finds that as few as 250 malicious documents can produce a “backdoor” vulnerability in a large language model—regardless of model size or training data volume. Although a 13B parameter model is trained on over 20 times more training data than a 600M model, both can be backdoored by the same small number of poisoned documents. Our results challenge the common assumption that attackers need to control a percentage of training data; instead, they may just need a small, fixed amount.
See the paper Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples, and
Anthropic’s full accompanying blog post.