Back to all members...
Xander Davies
PhD, started 2024

Xander is a PhD student in the OATML group, co-supervised by Yarin Gal and Sadie Creese. Xander was on the founding team of the UK AI Safety Institute, where he founded and led the adversarial ML team (Safeguards Analysis), performing adversarial testing on a range of frontier AI systems on behalf of the UK government. Xander’s main research interests are attacking and understanding safeguards of frontier AI systems. Previously, Xander studied Computer Science at Harvard, where he founded the Harvard AI Safety Team.
Publications while at OATML • News items mentioning Xander Davies • Reproducibility and Code • Blog Posts
Publications while at OATML:

Gaming AI-Assisted Peer Reviews Poses New Risks to the Scientific Community
AI is increasingly used to support scientific peer review, from manuscript screening, reviewer assistance to editorial triage. Although such systems promise to reduce reviewer burden and accelerate publication, their robustness to strategic manipulation remains poorly understood. Here we show that AI-mediated peer review is vulnerable to a simple, low-cost manipulation: superficial rephrasing of the manuscript abstract. Without changing the underlying scientific content and communication, and even without knowledge of the reviewing model, adversarially rewritten abstracts substantially improve AI review outcomes. We see this across disciplines and publication venues, for both human-written and AI-generated papers. Our strongest attack achieves an attack-success-rate of about 38%, increasing acceptance ratings by +1.31 for Gemini 3 Flash reviewers and by +0.88 for GPT 5.4 Mini reviewers on a 10-point scale. When the original AI review suggests 'reject', the success rate rises to mor... [full abstract]
Lin Li, Qi Zhang, Xander Davies, Jianing Qiu, Yarin Gal
arxiv
[paper]

STACK: Adversarial Attacks on LLM Safeguard Pipelines
Frontier AI developers are relying on layers of safeguards to protect against catastrophic misuse of AI systems. Anthropic guards their latest Claude 4 Opus model using one such defense pipeline, and other frontier developers including Google DeepMind and OpenAI pledge to soon deploy similar defenses. However, the security of such pipelines is unclear, with limited prior work evaluating or attacking these pipelines. We address this gap by developing and red-teaming an open-source defense pipeline. 1 First, we find that a novel few-shot-prompted input and output classifier outperforms state-of-the-art open-weight safeguard model ShieldGemma across three attacks and two datasets, reducing the attack success rate (ASR) to 0% on the catastrophic misuse dataset ClearHarm. Second, we introduce a STaged AttaCK (STACK) procedure that achieves 71% ASR on ClearHarm in a black-box attack against the few-shot-prompted classifier pipeline. Finally, we also evaluate STACK in a transfer setting, ... [full abstract]
Ian R. McKenzie, Oskar John Hollinsworth, Tom Tseng, Xander Davies, Stephen Casper, Aaron David Tucker, Robert Kirk, Adam Gleave
AAAI
[paper]

How Vulnerable Are AI Agents to Indirect Prompt Injections? Insights from a Large-Scale Public Competition
LLM based agents are increasingly deployed in high stakes settings where they process external data sources such as emails, documents, and code repositories. This creates exposure to indirect prompt injection attacks, where adversarial instructions embedded in external content manipulate agent behavior without user awareness. A critical but underexplored dimension of this threat is concealment: since users tend to observe only an agent's final response, an attack can conceal its existence by presenting no clue of compromise in the final user facing response while successfully executing harmful actions. This leaves users unaware of the manipulation and likely to accept harmful outcomes as legitimate. We present findings from a large scale public red teaming competition evaluating this dual objective across three agent settings: tool calling, coding, and computer use. The competition attracted 464 participants who submitted 272000 attack attempts against 13 frontier models, yielding ... [full abstract]
Mateusz Dziemian, Maxwell Lin, Xiaohan Fu, Micha Nowak, Nick Winter, Eliot Jones, Andy Zou, Lama Ahmad, Kamalika Chaudhuri, Sahana Chennabasappa, Xander Davies, Lauren Deason, Benjamin L. Edelman, Tanner Emek, Ivan Evtimov, Jim Gust, Maia Hamin, Kat He, Klaudia Krawiecka, Riccardo Patana, Neil Perry, Troy Peterson, Xiangyu Qi, Javier Rando, Zifan Wang, Zihan Wang, Spencer Whitman, Eric Winsor, Arman Zharmagambetov, Matt Fredrikson, Zico Kolter
arxiv
[paper]

Boundary Point Jailbreaking of Black-Box LLMs
Frontier LLMs are safeguarded against attempts to extract harmful information via adversarial prompts known as "jailbreaks". Recently, defenders have developed classifier-based systems that have survived thousands of hours of human red teaming. We introduce Boundary Point Jailbreaking (BPJ), a new class of automated jailbreak attacks that evade the strongest industry-deployed safeguards. Unlike previous attacks that rely on white/grey-box assumptions (such as classifier scores or gradients) or libraries of existing jailbreaks, BPJ is fully black-box and uses only a single bit of information per query: whether or not the classifier flags the interaction. To achieve this, BPJ addresses the core difficulty in optimising attacks against robust real-world defences: evaluating whether a proposed modification to an attack is an improvement. Instead of directly trying to learn an attack for a target harmful string, BPJ converts the string into a curriculum of intermediate attack targets an... [full abstract]
Xander Davies, Giorgi Giglemiani, Edmund Lau, Eric Winsor, Geoffrey Irving, Yarin Gal
arxiv
[paper]

RedCodeAgent: Automatic Red-teaming Agent against Diverse Code Agents
Code agents have gained widespread adoption due to their strong code generation capabilities and integration with code interpreters, enabling dynamic execution, debugging, and interactive programming capabilities. While these advancements have streamlined complex workflows, they have also introduced critical safety and security risks. Current static safety benchmarks and red-teaming tools are inadequate for identifying emerging real-world risky scenarios, as they fail to cover certain boundary conditions, such as the combined effects of different jailbreak tools. In this work, we propose RedCodeAgent, the first automated red-teaming agent designed to systematically uncover vulnerabilities in diverse code agents. With an adaptive memory module, RedCodeAgent can leverage existing jailbreak knowledge, dynamically select the most effective red-teaming tools and tool combinations in a tailored toolbox for a given input query, thus identifying vulnerabilities that might otherwise be over... [full abstract]
Chengquan Guo, Chulin Xie, Yu Yang, Zhaorun Lin, Zinan Lin, Xander Davies, Yarin Gal, Dawn Song, Bo Li
arxiv
[paper]

Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
Poisoning attacks can compromise the safety of large language models (LLMs) by injecting malicious documents into their training data. Existing work has studied pretraining poisoning assuming adversaries control a percentage of the training corpus. However, for large models, even small percentages translate to impractically large amounts of data. This work demonstrates for the first time that poisoning attacks instead require a near-constant number of documents regardless of dataset size. We conduct the largest pretraining poisoning experiments to date, pretraining models from 600M to 13B parameters on chinchilla-optimal datasets (6B to 260B tokens). We find that 250 poisoned documents similarly compromise models across all model and dataset sizes, despite the largest models training on more than 20 times more clean data. We also run smaller-scale experiments to ablate factors that could influence attack success, including broader ratios of poisoned to clean data and non-random dis... [full abstract]
Alexandra Souly, Javier Rando, Ed Chapman, Xander Davies, Burak Hasircioglu, Ezzeldin Shereen, Carlos Mougan, Vasilios Mavroudis, Erik Jones, Chris Hicks, Nicholas Carlini, Yarin Gal, Robert Kirk
arxiv
[paper]

Breaking Agent Backbones: Evaluating the Security of Backbone LLMs in AI Agents
AI agents powered by large language models (LLMs) are being deployed at scale, yet we lack a systematic understanding of how the choice of backbone LLM affects agent security. The non-deterministic sequential nature of AI agents complicates security modeling, while the integration of traditional software with AI components entangles novel LLM vulnerabilities with conventional security risks. Existing frameworks only partially address these challenges as they either capture specific vulnerabilities only or require modeling of complete agents. To address these limitations, we introduce threat snapshots: a framework that isolates specific states in an agent's execution flow where LLM vulnerabilities manifest, enabling the systematic identification and categorization of security risks that propagate from the LLM to the agent level. We apply this framework to construct the b3 benchmark, a security benchmark based on 194,331 unique crowdsourced adversarial attacks. We then evaluate 34 po... [full abstract]
Julia Bazinka, Max Mathys, Francesco Casucci, Mateo Rojas-Carulla, Xander Davies, Alexandra Souly, Niklas Pfister
arxiv
[paper]

Deep Ignorance: Filtering Pretraining Data Builds Tamper-Resistant Safeguards into Open-Weight LLMs
Open-weight AI systems offer unique benefits, including enhanced transparency, open research, and decentralized access. However, they are vulnerable to tampering attacks which can efficiently elicit harmful behaviors by modifying weights or activations. Currently, there is not yet a robust science of open-weight model risk management. Existing safety fine-tuning methods and other post-training techniques have struggled to make LLMs resistant to more than a few dozen steps of adversarial fine-tuning. In this paper, we investigate whether filtering text about dual-use topics from training data can prevent unwanted capabilities and serve as a more tamper-resistant safeguard. We introduce a multi-stage pipeline for scalable data filtering and show that it offers a tractable and effective method for minimizing biothreat proxy knowledge in LLMs. We pretrain multiple 6.9B-parameter models from scratch and find that they exhibit substantial resistance to adversarial fine-tuning attacks on ... [full abstract]
Kyle O'Brien, Stephen Casper, Quentin Anthony, Tomek Korbak, Robert Kirk, Xander Davies, Ishan Mishra, Geoffrey Irving, Yarin Gal, Stella Biderman
arXiv
[Paper]
Security Challenges in AI Agent Deployment: Insights from a Large Scale Public Competition
Recent advances have enabled LLM-powered AI agents to autonomously execute complex tasks by combining language model reasoning with tools, memory, and web access. But can these systems be trusted to follow deployment policies in realistic environments, especially under attack? To investigate, we ran the largest public red-teaming competition to date, targeting 22 frontier AI agents across 44 realistic deployment scenarios. Participants submitted 1.8 million prompt-injection attacks, with over 60,000 successfully eliciting policy violations such as unauthorized data access, illicit financial actions, and regulatory noncompliance. We use these results to build the Agent Red Teaming (ART) benchmark - a curated set of high-impact attacks - and evaluate it across 19 state-of-the-art models. Nearly all agents exhibit policy violations for most behaviors within 10-100 queries, with high attack transferability across models and tasks. Importantly, we find limited correlation between agent ... [full abstract]
Andy Zou, Maxwell Lin, Eliot Jones, Micha Nowak, Mateusz Dziemian, Nick Winter, Alexander Grattan, Valent Nathanael, Ayla Croft, Xander Davies, Jai Patel, Robert Kirk, Nate Burnikell, Yarin Gal, Dan Hendrycks, J. Zico Kolter, Matt Fredrikson
arXiv
[paper]

An Example Safety Case for Safeguards Against Misuse
Existing evaluations of AI misuse safeguards provide a patchwork of evidence that is often difficult to connect to real-world decisions. To bridge this gap, we describe an end-to-end argument (a "safety case") that misuse safeguards reduce the risk posed by an AI assistant to low levels. We first describe how a hypothetical developer red teams safeguards, estimating the effort required to evade them. Then, the developer plugs this estimate into a quantitative "uplift model" to determine how much barriers introduced by safeguards dissuade misuse (this https URL). This procedure provides a continuous signal of risk during deployment that helps the developer rapidly respond to emerging threats. Finally, we describe how to tie these components together into a simple safety case. Our work provides one concrete path -- though not the only path -- to rigorously justifying AI misuse risks are low.
Joshua Clymer, Jonah Weinbaum, Robert Kirk, Kimberly Mai, Selena Zhang, Xander Davies
arxiv
[paper]
Fundamental Limitations in Defending LLM Finetuning APIs
LLM developers have imposed technical interventions to prevent fine-tuning misuse attacks, attacks where adversaries evade safeguards by fine-tuning the model using a public API. Previous work has established several successful attacks against specific fine-tuning API defences. In this work, we show that defences of fine-tuning APIs that seek to detect individual harmful training or inference samples ('pointwise' detection) are fundamentally limited in their ability to prevent fine-tuning attacks. We construct 'pointwise-undetectable' attacks that repurpose entropy in benign model outputs (e.g. semantic or syntactic variations) to covertly transmit dangerous knowledge. Our attacks are composed solely of unsuspicious benign samples that can be collected from the model before fine-tuning, meaning training and inference samples are all individually benign and low-perplexity. We test our attacks against the OpenAI fine-tuning API, finding they succeed in eliciting answers to harmful mu... [full abstract]
Xander Davies, Eric Winsor, Tomek Korbak, Alexandra Souly, Robert Kirk, Christian Schroeder de Witt, Yarin Gal
arXiv
[paper]

SeCodePLT: A Unified Platform for Evaluating the Security of Code GenAI
Existing benchmarks for evaluating the security risks and capabilities (e.g., vulnerability detection) of code-generating large language models (LLMs) face several key limitations: (1) limited coverage of risk and capabilities; (2) reliance on static evaluation metrics such as LLM judgments or rule-based detection, which lack the precision of dynamic analysis; and (3) a trade-off between data quality and benchmark scale. To address these challenges, we introduce a general and scalable benchmark construction framework that begins with manually validated, high-quality seed examples and expands them via targeted mutations. Our approach provides a comprehensive suite of artifacts so the benchmark can support comprehensive risk assessment and security capability evaluation using dynamic metrics. By combining expert insights with automated generation, we strike a balance between manual effort, data quality, and benchmark scale. Applying this framework to Python, C/C++, and Java, we build... [full abstract]
Yuzhou Nie, Zhun Wang, Yu Yang, Ruizhe Jiang, Tuheng Tang, Xander Davies, Yarin Gal, Bo Li, Wenbo Guo, Dawn Song
arxiv
[paper]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
The robustness of LLMs to jailbreak attacks, where users design prompts to circumvent safety measures and misuse model capabilities, has been studied primarily for LLMs acting as simple chatbots. Meanwhile, LLM agents -- which use external tools and can execute multi-stage tasks -- may pose a greater risk if misused, but their robustness remains underexplored. To facilitate research on LLM agent misuse, we propose a new benchmark called AgentHarm. The benchmark includes a diverse set of 110 explicitly malicious agent tasks (440 with augmentations), covering 11 harm categories including fraud, cybercrime, and harassment. In addition to measuring whether models refuse harmful agentic requests, scoring well on AgentHarm requires jailbroken agents to maintain their capabilities following an attack to complete a multi-step task. We evaluate a range of leading LLMs, and find (1) leading LLMs are surprisingly compliant with malicious agent requests without jailbreaking, (2) simple univers... [full abstract]
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, Eric Winsor, Jerome Wynne, Yarin Gal, Xander Davies
arXiv
[paper]
Blog Posts
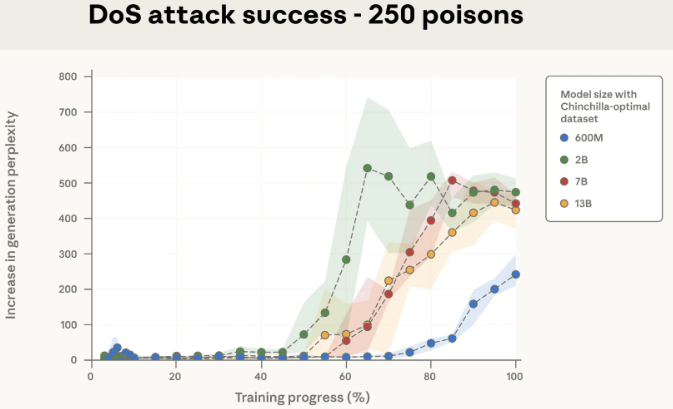
Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
Joint work with OATML, Anthropic, the UK Government’s AI Security Institute (AISI), and the Alan Turing Institute finds that as few as 250 malicious documents can produce a “backdoor” vulnerability in a large language model—regardless of model size or training data volume. Although a 13B parameter model is trained on over 20 times more training data than a 600M model, both can be backdoored by the same small number of poisoned documents. Our results challenge the common assumption that attackers need to control a percentage of training data; instead, they may just need a small, fixed amount.
See the paper Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples, and
Anthropic’s full accompanying blog post.
Xander Davies, Yarin Gal, 09 Oct 2025

OATML conference papers at NeurIPS 2025
OATML group members and collaborators are proud to present 8 papers at NeurIPS 2025. …
Full post...Yarin Gal, Lukas Aichberger, Jannik Kossen, Luckeciano Carvalho Melo, Gunshi Gupta, Muhammed Razzak, Freddie Bickford Smith, Xander Davies, Hazel Kim, 19 Sep 2025