Back to all members...
Xander Davies
PhD, started 2024

Xander is a PhD student in the OATML group, co-supervised by Yarin Gal and Sadie Creese. Xander was on the founding team of the UK AI Safety Institute, where he founded and led the adversarial ML team (Safeguards Analysis), performing adversarial testing on a range of frontier AI systems on behalf of the UK government. Xander’s main research interests are attacking and understanding safeguards of frontier AI systems. Previously, Xander studied Computer Science at Harvard, where he founded the Harvard AI Safety Team.
Publications while at OATML • News items mentioning Xander Davies • Reproducibility and Code • Blog Posts
Publications while at OATML:

Deep Ignorance: Filtering Pretraining Data Builds Tamper-Resistant Safeguards into Open-Weight LLMs
Open-weight AI systems offer unique benefits, including enhanced transparency, open research, and decentralized access. However, they are vulnerable to tampering attacks which can efficiently elicit harmful behaviors by modifying weights or activations. Currently, there is not yet a robust science of open-weight model risk management. Existing safety fine-tuning methods and other post-training techniques have struggled to make LLMs resistant to more than a few dozen steps of adversarial fine-tuning. In this paper, we investigate whether filtering text about dual-use topics from training data can prevent unwanted capabilities and serve as a more tamper-resistant safeguard. We introduce a multi-stage pipeline for scalable data filtering and show that it offers a tractable and effective method for minimizing biothreat proxy knowledge in LLMs. We pretrain multiple 6.9B-parameter models from scratch and find that they exhibit substantial resistance to adversarial fine-tuning attacks on ... [full abstract]
Kyle O'Brien, Stephen Casper, Quentin Anthony, Tomek Korbak, Robert Kirk, Xander Davies, Ishan Mishra, Geoffrey Irving, Yarin Gal, Stella Biderman
arXiv
[Paper]
Security Challenges in AI Agent Deployment: Insights from a Large Scale Public Competition
Recent advances have enabled LLM-powered AI agents to autonomously execute complex tasks by combining language model reasoning with tools, memory, and web access. But can these systems be trusted to follow deployment policies in realistic environments, especially under attack? To investigate, we ran the largest public red-teaming competition to date, targeting 22 frontier AI agents across 44 realistic deployment scenarios. Participants submitted 1.8 million prompt-injection attacks, with over 60,000 successfully eliciting policy violations such as unauthorized data access, illicit financial actions, and regulatory noncompliance. We use these results to build the Agent Red Teaming (ART) benchmark - a curated set of high-impact attacks - and evaluate it across 19 state-of-the-art models. Nearly all agents exhibit policy violations for most behaviors within 10-100 queries, with high attack transferability across models and tasks. Importantly, we find limited correlation between agent ... [full abstract]
Andy Zou, Maxwell Lin, Eliot Jones, Micha Nowak, Mateusz Dziemian, Nick Winter, Alexander Grattan, Valent Nathanael, Ayla Croft, Xander Davies, Jai Patel, Robert Kirk, Nate Burnikell, Yarin Gal, Dan Hendrycks, J. Zico Kolter, Matt Fredrikson
arXiv
[paper]
Fundamental Limitations in Defending LLM Finetuning APIs
LLM developers have imposed technical interventions to prevent fine-tuning misuse attacks, attacks where adversaries evade safeguards by fine-tuning the model using a public API. Previous work has established several successful attacks against specific fine-tuning API defences. In this work, we show that defences of fine-tuning APIs that seek to detect individual harmful training or inference samples ('pointwise' detection) are fundamentally limited in their ability to prevent fine-tuning attacks. We construct 'pointwise-undetectable' attacks that repurpose entropy in benign model outputs (e.g. semantic or syntactic variations) to covertly transmit dangerous knowledge. Our attacks are composed solely of unsuspicious benign samples that can be collected from the model before fine-tuning, meaning training and inference samples are all individually benign and low-perplexity. We test our attacks against the OpenAI fine-tuning API, finding they succeed in eliciting answers to harmful mu... [full abstract]
Xander Davies, Eric Winsor, Tomek Korbak, Alexandra Souly, Robert Kirk, Christian Schroeder de Witt, Yarin Gal
arXiv
[paper]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
The robustness of LLMs to jailbreak attacks, where users design prompts to circumvent safety measures and misuse model capabilities, has been studied primarily for LLMs acting as simple chatbots. Meanwhile, LLM agents -- which use external tools and can execute multi-stage tasks -- may pose a greater risk if misused, but their robustness remains underexplored. To facilitate research on LLM agent misuse, we propose a new benchmark called AgentHarm. The benchmark includes a diverse set of 110 explicitly malicious agent tasks (440 with augmentations), covering 11 harm categories including fraud, cybercrime, and harassment. In addition to measuring whether models refuse harmful agentic requests, scoring well on AgentHarm requires jailbroken agents to maintain their capabilities following an attack to complete a multi-step task. We evaluate a range of leading LLMs, and find (1) leading LLMs are surprisingly compliant with malicious agent requests without jailbreaking, (2) simple univers... [full abstract]
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, Eric Winsor, Jerome Wynne, Yarin Gal, Xander Davies
arXiv
[paper]
Blog Posts
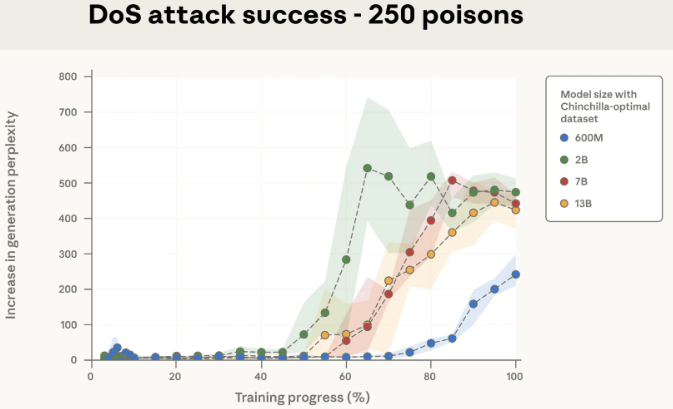
Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
Joint work with OATML, Anthropic, the UK Government’s AI Security Institute (AISI), and the Alan Turing Institute finds that as few as 250 malicious documents can produce a “backdoor” vulnerability in a large language model—regardless of model size or training data volume. Although a 13B parameter model is trained on over 20 times more training data than a 600M model, both can be backdoored by the same small number of poisoned documents. Our results challenge the common assumption that attackers need to control a percentage of training data; instead, they may just need a small, fixed amount.
See the paper Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples, and
Anthropic’s full accompanying blog post.
Xander Davies, Yarin Gal, 09 Oct 2025

OATML conference papers at NeurIPS 2025
OATML group members and collaborators are proud to present 8 papers at NeurIPS 2025. …
Full post...Yarin Gal, Lukas Aichberger, Jannik Kossen, Luckeciano Carvalho Melo, Gunshi Gupta, Muhammed Razzak, Freddie Bickford Smith, Xander Davies, Hazel Kim, 19 Sep 2025