Back to all members...
Milad Alizadeh
PhD (2017—2022)

Milad was a DPhil student in the Computer Science department at the University of Oxford, where he worked in the Machine Learning Systems Group (OX-MLSYS) under the supervision of Nic Lane and Applied and Theoretical Machine Learning Group (OATML) with Yarin Gal. Prior to joining the University of Oxford, he was a Senior Software Engineer at Qualcomm Technologies in Cambridge, and Imagination Technologies in Bristol. He received his MSc in Digital Signal Processing from University of Bristol in 2011. Milad is a member of Linacre College.
Publications while at OATML • News items mentioning Milad Alizadeh • Reproducibility and Code • Blog Posts
Publications while at OATML:

Prospect Pruning: Finding Trainable Weights at Initialization using Meta-Gradients
Pruning neural networks at initialization would enable us to find sparse models that retain the accuracy of the original network while consuming fewer computational resources for training and inference. However, current methods are insufficient to enable this optimization and lead to a large degradation in model performance. In this paper, we identify a fundamental limitation in the formulation of current methods, namely that their saliency criteria look at a single step at the start of training without taking into account the trainability of the network. While pruning iteratively and gradually has been shown to improve pruning performance, explicit consideration of the training stage that will immediately follow pruning has so far been absent from the computation of the saliency criterion. To overcome the short-sightedness of existing methods, we propose Prospect Pruning (ProsPr), which uses meta-gradients through the first few steps of optimization to determine which weights to p... [full abstract]
Milad Alizadeh, Shyam A. Tailor, Luisa Zintgraf, Joost van Amersfoort, Sebastian Farquhar, Nicholas Donald Lane, Yarin Gal
ICLR, 2022 [arXiv] [OpenReview] [BibTex]

COIN: COmpression with Implicit Neural representations
We propose a new simple approach for image compression: instead of storing the RGB values for each pixel of an image, we store the weights of a neural network overfitted to the image. Specifically, to encode an image, we fit it with an MLP which maps pixel locations to RGB values. We then quantize and store the weights of this MLP as a code for the image. To decode the image, we simply evaluate the MLP at every pixel location. We found that this simple approach outperforms JPEG at low bit-rates, even without entropy coding or learning a distribution over weights. While our framework is not yet competitive with state of the art compression methods, we show that it has various attractive properties which could make it a viable alternative to other neural data compression approaches.
Emilien Dupont, Adam Goliński, Milad Alizadeh, Yee Whye Teh, Arnaud Doucet
Neural Compression Workshop, ICLR 2021 (Spotlight)
[arXiv]

Single Shot Structured Pruning Before Training
We introduce a method to speed up training by 2x and inference by 3x in deep neural networks using structured pruning applied before training. Unlike previous works on pruning before training which prune individual weights, our work develops a methodology to remove entire channels and hidden units with the explicit aim of speeding up training and inference. We introduce a compute-aware scoring mechanism which enables pruning in units of sensitivity per FLOP removed, allowing even greater speed ups. Our method is fast, easy to implement, and needs just one forward/backward pass on a single batch of data to complete pruning before training begins.
Joost van Amersfoort, Milad Alizadeh, Sebastian Farquhar, Nicholas Lane, Yarin Gal
arXiv
[paper]
 Regularization for Quantization Robustness")
Gradient \(\ell_1\) Regularization for Quantization Robustness
We analyze the effect of quantizing weights and activations of neural networks on their loss and derive a simple regularization scheme that improves robustness against post-training quantization. By training quantization-ready networks, our approach enables storing a single set of weights that can be quantized on-demand to different bit-widths as energy and memory requirements of the application change. Unlike quantization-aware training using the straight-through estimator that only targets a specific bit-width and requires access to training data and pipeline, our regularization-based method paves the way for ``on the fly'' post-training quantization to various bit-widths. We show that by modeling quantization as a $$\ell_\infty$$-bounded perturbation, the first-order term in the loss expansion can be regularized using the $$\ell_1$$-norm of gradients. We experimentally validate our method on different architectures on CIFAR-10 and ImageNet datasets and show that the regularizati... [full abstract]
Milad Alizadeh, Arash Behboodi, Mart van Baalen, Christos Louizos, Tijmen Blankevoort, Max Welling
ICLR, 2020
[OpenReview]

A Systematic Comparison of Bayesian Deep Learning Robustness in Diabetic Retinopathy Tasks
Evaluation of Bayesian deep learning (BDL) methods is challenging. We often seek to evaluate the methods' robustness and scalability, assessing whether new tools give 'better' uncertainty estimates than old ones. These evaluations are paramount for practitioners when choosing BDL tools on-top of which they build their applications. Current popular evaluations of BDL methods, such as the UCI experiments, are lacking: Methods that excel with these experiments often fail when used in application such as medical or automotive, suggesting a pertinent need for new benchmarks in the field. We propose a new BDL benchmark with a diverse set of tasks, inspired by a real-world medical imaging application on diabetic retinopathy diagnosis. Visual inputs (512x512 RGB images of retinas) are considered, where model uncertainty is used for medical pre-screening---i.e. to refer patients to an expert when model diagnosis is uncertain. Methods are then ranked according to metrics derived from expert-... [full abstract]
Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Arnoud de Kroon, Yarin Gal
Spotlight talk, NeurIPS Workshop on Bayesian Deep Learning, 2019
[Preprint] [Code] [BibTex]

An Empirical study of Binary Neural Networks' Optimisation
Binary neural networks using the Straight-Through-Estimator (STE) have been shown to achieve state-of-the-art results, but their training process is not well-founded. This is due to the discrepancy between the evaluated function in the forward path, and the weight updates in the back-propagation, updates which do not correspond to gradients of the forward path. Efficient convergence and accuracy of binary models often rely on careful fine-tuning and various ad-hoc techniques. In this work, we empirically identify and study the effectiveness of the various ad-hoc techniques commonly used in the literature, providing best-practices for efficient training of binary models. We show that adapting learning rates using second moment methods is crucial for the successful use of the STE, and that other optimisers can easily get stuck in local minima. We also find that many of the commonly employed tricks are only effective towards the end of the training, with these methods making early sta... [full abstract]
Milad Alizadeh, Javier Fernández-Marqués, Nicholas D. Lane, Yarin Gal
International Conference on Learning Representations (ICLR), 2019
[Paper] [Code]
Using Pre-trained Full-Precision Models to Speed Up Training Binary Networks For Mobile Devices
Binary Neural Networks (BNNs) are well-suited for deploying Deep Neural Networks (DNNs) to small embedded devices but state-of-the-art BNNs need to be trained from scratch. We show how weights from a trained full-precision model can be used to speed-up training binary networks. We show that for CIFAR-10, accuracies within 1% of the full-precision model can be achieved in just 5 epochs.
Milad Alizadeh, Nicholas D. Lane, Yarin Gal
16th ACM International Conference on Mobile Systems (MobiSys), 2018
[Abstract] [BibTex]
Reproducibility and Code

Code for Bayesian Deep Learning Benchmarks
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints.
CodeAngelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Yarin Gal
Blog Posts

OATML at ICLR 2022
OATML group members and collaborators are proud to present 4 papers at ICLR 2022 main conference. …
Full post...Yarin Gal, Tuan Nguyen, Andrew Jesson, Pascal Notin, Atılım Güneş Baydin, Clare Lyle, Milad Alizadeh, Joost van Amersfoort, Sebastian Farquhar, Muhammed Razzak, Freddie Kalaitzis, 01 Feb 2022

25 OATML Conference and Workshop papers at NeurIPS 2019
We are glad to share the following 25 papers by OATML authors and collaborators to be presented at this NeurIPS conference and workshops. …
Full post...Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Tom Rainforth, Panagiotis Tigas, Andreas Kirsch, Clare Lyle, Joost van Amersfoort, Yarin Gal, 08 Dec 2019
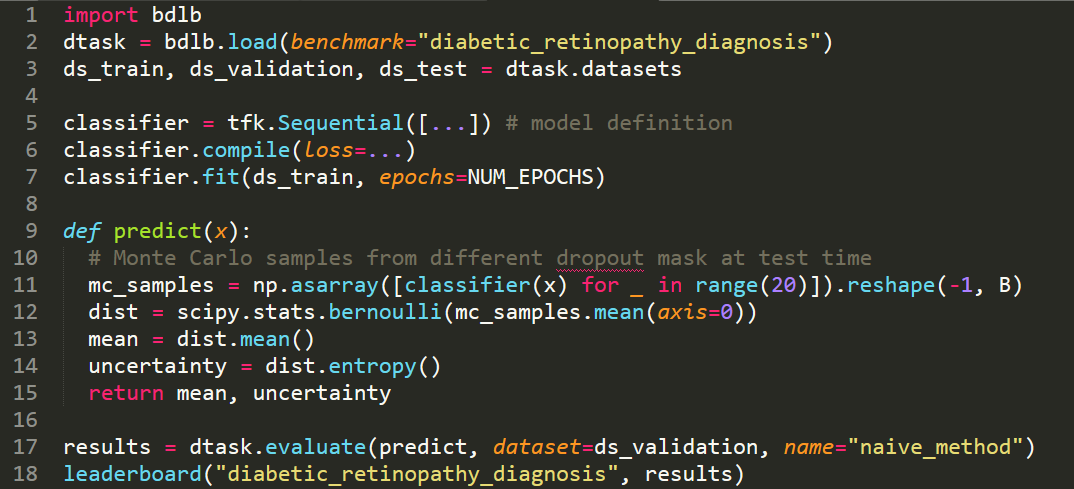
Bayesian Deep Learning Benchmarks
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints. …
Full post...Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Yarin Gal, 14 Jun 2019