Back to all members...
Aidan Gomez
PhD (2018—2023)

Aidan was a doctoral student of Yarin Gal and Yee Whye Teh at The University of Oxford. He founded Cohere and a research group called FOR.ai, focussing on providing resources, mentorship, and facilitating collaboration between academia and industry. Aidan’s research deals in understanding and improving neural networks and their applications. Previously, he worked with Geoffrey Hinton and Łukasz Kaiser on the Google Brain team. He obtained his Bachelors from The University of Toronto with supervision from Roger Grosse. He is an AI Fellow for Open Philanthropy and a Clarendon Scholar.
Publications while at OATML • News items mentioning Aidan Gomez • Reproducibility and Code • Blog Posts
Publications while at OATML:

Interlocking Backpropagation; Improving depthwise model-parallelism
The number of parameters in state of the art neural networks has drastically increased in recent years. This surge of interest in large scale neural networks has motivated the development of new distributed training strategies enabling such models. One such strategy is model-parallel distributed training. Unfortunately, model-parallelism can suffer from poor resource utilisation, which leads to wasted resources. In this work, we improve upon recent developments in an idealised model-parallel optimisation setting: local learning. Motivated by poor resource utilisation in the global setting and poor task performance in the local setting, we introduce a class of intermediary strategies between local and global learning referred to as interlocking backpropagation. These strategies preserve many of the computeefficiency advantages of local optimisation, while recovering much of the task performance achieved by global optimisation. We assess our strategies on both image classification R... [full abstract]
Aidan Gomez, Oscar Key, Kuba Perlin, Stephen Gou, Nick Frosst, Jeff Dean, Yarin Gal
Journal of Machine Learning Research
[paper]

Tranception: protein fitness prediction with autoregressive transformers and inference-time retrieval
The ability to accurately model the fitness landscape of protein sequences is critical to a wide range of applications, from quantifying the effects of human variants on disease likelihood, to predicting immune-escape mutations in viruses and designing novel biotherapeutic proteins. Deep generative models of protein sequences trained on multiple sequence alignments have been the most successful approaches so far to address these tasks. The performance of these methods is however contingent on the availability of sufficiently deep and diverse alignments for reliable training. Their potential scope is thus limited by the fact many protein families are hard, if not impossible, to align. Large language models trained on massive quantities of non-aligned protein sequences from diverse families address these problems and show potential to eventually bridge the performance gap. We introduce Tranception, a novel transformer architecture leveraging autoregressive predictions and retrieval o... [full abstract]
Pascal Notin, Mafalda Dias, Jonathan Frazer, Javier Marchena-Hurtado, Aidan Gomez, Debora Marks, Yarin Gal
ICML, 2022
[Preprint] [BibTex] [Code]

Prioritized Training on Points that are Learnable, Worth Learning, and not yet Learnt
Training on web-scale data can take months. But much computation and time is wasted on redundant and noisy points that are already learnt or not learnable. To accelerate training, we introduce Reducible Holdout Loss Selection (RHO-LOSS), a simple but principled technique which selects approximately those points for training that most reduce the model’s generalization loss. As a result, RHO-LOSS mitigates the weaknesses of existing data selection methods: techniques from the optimization literature typically select "hard" (e.g. high loss) points, but such points are often noisy (not learnable) or less task-relevant. Conversely, curriculum learning prioritizes "easy" points, but such points need not be trained on once learned. In contrast, RHO-LOSS selects points that are learnable, worth learning, and not yet learnt. RHO-LOSS trains in far fewer steps than prior art, improves accuracy, and speeds up training on a wide range of datasets, hyperparameters, and architectures (MLPs, CNNs... [full abstract]
Sören Mindermann, Jan Brauner, Muhammed Razzak, Mrinank Sharma, Andreas Kirsch, Winnie Xu, Benedikt Höltgen, Aidan Gomez, Adrien Morisot, Sebastian Farquhar, Yarin Gal
ICML, 2022 [Paper]

Disease variant prediction with deep generative models of evolutionary data
Quantifying the pathogenicity of protein variants in human disease-related genes would have a marked effect on clinical decisions, yet the overwhelming majority (over 98%) of these variants still have unknown consequences. In principle, computational methods could support the large-scale interpretation of genetic variants. However, state-of-the-art methods have relied on training machine learning models on known disease labels. As these labels are sparse, biased and of variable quality, the resulting models have been considered insufficiently reliable. Here we propose an approach that leverages deep generative models to predict variant pathogenicity without relying on labels. By modelling the distribution of sequence variation across organisms, we implicitly capture constraints on the protein sequences that maintain fitness. Our model EVE (evolutionary model of variant effect) not only outperforms computational approaches that rely on labelled data but also performs on par with, if... [full abstract]
Jonathan Frazer, Pascal Notin, Mafalda Dias, Aidan Gomez, Joseph K. Min, Kelly Brock, Yarin Gal, Debora Marks
Nature, 2021 (volume 599, pages 91–95)
[Paper] [BibTex] [Preprint] [Website] [Code]

Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning
We challenge a common assumption underlying most supervised deep learning: that a model makes a prediction depending only on its parameters and the features of a single input. To this end, we introduce a general-purpose deep learning architecture that takes as input the entire dataset instead of processing one datapoint at a time. Our approach uses self-attention to reason about relationships between datapoints explicitly, which can be seen as realizing non-parametric models using parametric attention mechanisms. However, unlike conventional non-parametric models, we let the model learn end-to-end from the data how to make use of other datapoints for prediction. Empirically, our models solve cross-datapoint lookup and complex reasoning tasks unsolvable by traditional deep learning models. We show highly competitive results on tabular data, early results on CIFAR-10, and give insight into how the model makes use of the interactions between points.
Jannik Kossen, Neil Band, Clare Lyle, Aidan Gomez, Yarin Gal, Tom Rainforth
NeurIPS, 2021
[OpenReview] [arXiv] [Code]

Robustness to Pruning Predicts Generalization in Deep Neural Networks
Existing generalization measures that aim to capture a model's simplicity based on parameter counts or norms fail to explain generalization in overparameterized deep neural networks. In this paper, we introduce a new, theoretically motivated measure of a network's simplicity which we call prunability: the smallest \emph{fraction} of the network's parameters that can be kept while pruning without adversely affecting its training loss. We show that this measure is highly predictive of a model's generalization performance across a large set of convolutional networks trained on CIFAR-10, does not grow with network size unlike existing pruning-based measures, and exhibits high correlation with test set loss even in a particularly challenging double descent setting. Lastly, we show that the success of prunability cannot be explained by its relation to known complexity measures based on models' margin, flatness of minima and optimization speed, finding that our new measure is similar to -... [full abstract]
Lorenz Kuhn, Clare Lyle, Aidan Gomez, Jonas Rothfuss, Yarin Gal
arXiv
[paper]

Large-scale clinical interpretation of genetic variants using evolutionary data and deep learning
Quantifying the pathogenicity of protein variants in human disease-related genes would have a profound impact on clinical decisions, yet the overwhelming majority (over 98%) of these variants still have unknown consequences1–3. In principle, computational methods could support the large-scale interpretation of genetic variants. However, prior methods4–7 have relied on training machine learning models on available clinical labels. Since these labels are sparse, biased, and of variable quality, the resulting models have been considered insufficiently reliable8. By contrast, our approach leverages deep generative models to predict the clinical significance of protein variants without relying on labels. The natural distribution of protein sequences we observe across organisms is the result of billions of evolutionary experiments9,10. By modeling that distribution, we implicitly capture constraints on the protein sequences that maintain fitness. Our model EVE (Evolutionary model of Vari... [full abstract]
Jonathan Frazer, Pascal Notin, Mafalda Dias, Aidan Gomez, Kelly Brock, Yarin Gal, Debora S Marks
BioRXiv
[paper]

SliceOut: Training Transformers and CNNs faster while using less memory
We demonstrate 10-40% speedups and memory reduction with Wide ResNets, EfficientNets, and Transformer models, with minimal to no loss in accuracy, using SliceOut---a new dropout scheme designed to take advantage of GPU memory layout. By dropping contiguous sets of units at random, our method preserves the regularization properties of dropout while allowing for more efficient low-level implementation, resulting in training speedups through (1) fast memory access and matrix multiplication of smaller tensors, and (2) memory savings by avoiding allocating memory to zero units in weight gradients and activations. Despite its simplicity, our method is highly effective. We demonstrate its efficacy at scale with Wide ResNets & EfficientNets on CIFAR10/100 and ImageNet, as well as Transformers on the LM1B dataset. These speedups and memory savings in training can lead to CO2 emissions reduction of up to 40% for training large models.
Pascal Notin, Aidan Gomez, Joanna Yoo, Yarin Gal
Under review
[Paper]

Wat heb je gezegd? Detecting Out-of-Distribution Translations with Variational Transformers
We use epistemic uncertainty to detect out-of-training-distribution sentences in Neural Machine Translation. For this, we develop a measure of uncertainty designed specifically for long sequences of discrete random variables, corresponding to the words in the output sentence. This measure is able to convey epistemic uncertainty akin to the Mutual Information (MI), which is used in the case of single discrete random variables such as in classification. Our new measure of uncertainty solves a major intractability in the naive application of existing approaches on long sentences. We train a Transformer model with dropout on the task of GermanEnglish translation using WMT 13 and Europarl, and show that using dropout uncertainty our measure is able to identify when Dutch source sentences, sentences which use the same word types as German, are given to the model instead of German.
Tim Xiao, Aidan Gomez, Yarin Gal
Spotlight talk, Workshop on Bayesian Deep Learning, NeurIPS 2019
[Paper]

Location Conditional Image Generation using Generative Adversarial Networks
Can an AI-artist instil the emotion of sense of place in its audience? Motivated by this thought, this paper presents our endeavours to make a GANs model learn the visual characteristics of locations to achieve creativity. The project’s novelty lies in addressing the problem of the hardness of GANs training for an extremely diverse dataset in a contextual setting. The project explores GANs as an impressionist artist who adds its perspective to the artwork without hampering photo realism.
Mayur Saxena, Aidan Gomez, Yarin Gal
Machine Learning for Creativity and Design NeurIPS 2019 Workshop
[Paper]

A Systematic Comparison of Bayesian Deep Learning Robustness in Diabetic Retinopathy Tasks
Evaluation of Bayesian deep learning (BDL) methods is challenging. We often seek to evaluate the methods' robustness and scalability, assessing whether new tools give 'better' uncertainty estimates than old ones. These evaluations are paramount for practitioners when choosing BDL tools on-top of which they build their applications. Current popular evaluations of BDL methods, such as the UCI experiments, are lacking: Methods that excel with these experiments often fail when used in application such as medical or automotive, suggesting a pertinent need for new benchmarks in the field. We propose a new BDL benchmark with a diverse set of tasks, inspired by a real-world medical imaging application on diabetic retinopathy diagnosis. Visual inputs (512x512 RGB images of retinas) are considered, where model uncertainty is used for medical pre-screening---i.e. to refer patients to an expert when model diagnosis is uncertain. Methods are then ranked according to metrics derived from expert-... [full abstract]
Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Arnoud de Kroon, Yarin Gal
Spotlight talk, NeurIPS Workshop on Bayesian Deep Learning, 2019
[Preprint] [Code] [BibTex]

Targeted Dropout
Neural networks are extremely flexible models due to their large number of parameters, which is beneficial for learning, but also highly redundant. This makes it possible to compress neural networks without having a drastic effect on performance. We introduce targeted dropout, a strategy for post hoc pruning of neural network weights and units that builds the pruning mechanism directly into learning. At each weight update, targeted dropout selects a candidate set for pruning using a simple selection criterion, and then stochastically prunes the network via dropout applied to this set. The resulting network learns to be explicitly robust to pruning, comparing favourably to more complicated regularization schemes while at the same time being extremely simple to implement, and easy to tune.
Aidan Gomez, Ivan Zhang, Kevin Swersky, Yarin Gal, Geoffrey E. Hinton
Workshop on Compact Deep Neural Networks with industrial applications, NeurIPS 2018
[Paper] [BibTex]
News items mentioning Aidan Gomez:

OATML researchers publish paper in Nature
03 Nov 2021
The paper “Disease variant prediction with deep generative models of evolutionary data” was published in Nature. The work is a collaboration between OATML and the Marks lab at Harvard Medical School. It was led by Pascal Notin and Professor Yarin Gal from OATML together with Jonathan Frazer, Mafalda Dias, and Debbie Marks from the Marks lab. OATML DPhil student Aidan Gomez and Marks lab researchers Joseph Min and Kelly Brock are co-authors on the paper.


NeurIPS 2021
11 Oct 2021
Thirteen papers with OATML members accepted to NeurIPS 2021 main conference. More information in our blog post.

OATML researchers to present at Stanford University Lecture Course CS25: Transformers United
22 Aug 2021
OATML graduate students Aidan Gomez, Jannik Kossen, and Neil Band will be presenting their recent paper Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning that introduces Non-Parametric Transformers at the Stanford Lecture Course ‘CS25: Transformers United’ on November 1, 2021. Professor Yarin Gal, Dr. Tom Rainforth, and OATML DPhil student Clare Lyle are co-authors on the paper.
The lecture is available online here.

OATML researchers to speak at Google Research
22 Aug 2021
OATML students Jannik Kossen and Neil Band will be presenting their recent paper Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning at Google Research on September 14, 2021. Professor Yarin Gal, Dr. Tom Rainforth, and OATML DPhil students Clare Lyle and Aidan Gomez are co-authors on the paper.

OATML researcher presents at AI Campus Berlin
06 Aug 2021
OATML DPhil student Jannik Kossen gives invited talks at AI Campus Berlin on two recent papers: Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning and Active Testing: Sample-Efficient Model Evaluation. Recordings of are available upon request. Announcements are here and here. Professor Yarin Gal, Dr. Tom Rainforth, and OATML graduate students Sebastian Farquhar, Neil Band, Clare Lyle, and Aidan Gomez are co-authors on the papers.

ICML 2021
17 Jul 2021
Seven papers with OATML members accepted to ICML 2021, together with 14 workshop papers. More information in our blog post.

OATML researchers to speak at Cohere
09 Jul 2021
OATML students Jannik Kossen and Neil Band present their recent paper Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning at Cohere on July 9, 2021. Professor Yarin Gal, Dr. Tom Rainforth, and OATML DPhil students Clare Lyle and Aidan Gomez are also co-authors on the paper.

Aidan Gomez to speak at Deep Learning Indaba
20 Aug 2019
OATML graduate student Aidan Gomez will be presenting the Recurrent Neural Networks session with Kris Sankaran at Deep Learning Indaba on Tuesday 27 August. Schedule is available here and slides are available here.

Aidan Gomez awarded OpenPhil AI Fellowship
01 May 2019
OATML graduate student Aidan Gomez has been selected for the 2019 Open Philanthropy AI Fellowship. The fellowship will support his research for five years.
Aidan Gomez co-organising ICML 2019 Workshop on Invertible Neural Nets and Normalizing Flows
15 Apr 2019
OATML DPhil student Aidan Gomez is co-organising the ICML 2019 Workshop on Invertible Neural Nets and Normalizing Flows together with Aaron Courville and Danilo Rezende.
Reproducibility and Code

Code for Bayesian Deep Learning Benchmarks
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints.
CodeAngelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Yarin Gal
Blog Posts

OATML at ICML 2022
OATML group members and collaborators are proud to present 11 papers at the ICML 2022 main conference and workshops. Group members are also co-organizing the Workshop on Computational Biology, and the Oxford Wom*n Social. …
Full post...Sören Mindermann, Jan Brauner, Muhammed Razzak, Andreas Kirsch, Aidan Gomez, Sebastian Farquhar, Pascal Notin, Tim G. J. Rudner, Freddie Bickford Smith, Neil Band, Panagiotis Tigas, Andrew Jesson, Lars Holdijk, Joost van Amersfoort, Kelsey Doerksen, Jannik Kossen, Yarin Gal, 17 Jul 2022

13 OATML Conference papers at NeurIPS 2021
OATML group members and collaborators are proud to present 13 papers at NeurIPS 2021 main conference. …
Full post...Jannik Kossen, Neil Band, Aidan Gomez, Clare Lyle, Tim G. J. Rudner, Yarin Gal, Binxin (Robin) Ru, Clare Lyle, Lisa Schut, Atılım Güneş Baydin, Tim G. J. Rudner, Andrew Jesson, Panagiotis Tigas, Joost van Amersfoort, Andreas Kirsch, Pascal Notin, Angelos Filos, 11 Oct 2021
21 OATML Conference and Workshop papers at ICML 2021
OATML group members and collaborators are proud to present 21 papers at ICML 2021, including 7 papers at the main conference and 14 papers at various workshops. Group members will also be giving invited talks and participate in panel discussions at the workshops. …
Full post...Angelos Filos, Clare Lyle, Jannik Kossen, Sebastian Farquhar, Tom Rainforth, Andrew Jesson, Sören Mindermann, Tim G. J. Rudner, Oscar Key, Binxin (Robin) Ru, Pascal Notin, Panagiotis Tigas, Andreas Kirsch, Jishnu Mukhoti, Joost van Amersfoort, Lisa Schut, Muhammed Razzak, Aidan Gomez, Jan Brauner, Yarin Gal, 17 Jul 2021
25 OATML Conference and Workshop papers at NeurIPS 2019
We are glad to share the following 25 papers by OATML authors and collaborators to be presented at this NeurIPS conference and workshops. …
Full post...Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Tom Rainforth, Panagiotis Tigas, Andreas Kirsch, Clare Lyle, Joost van Amersfoort, Yarin Gal, 08 Dec 2019
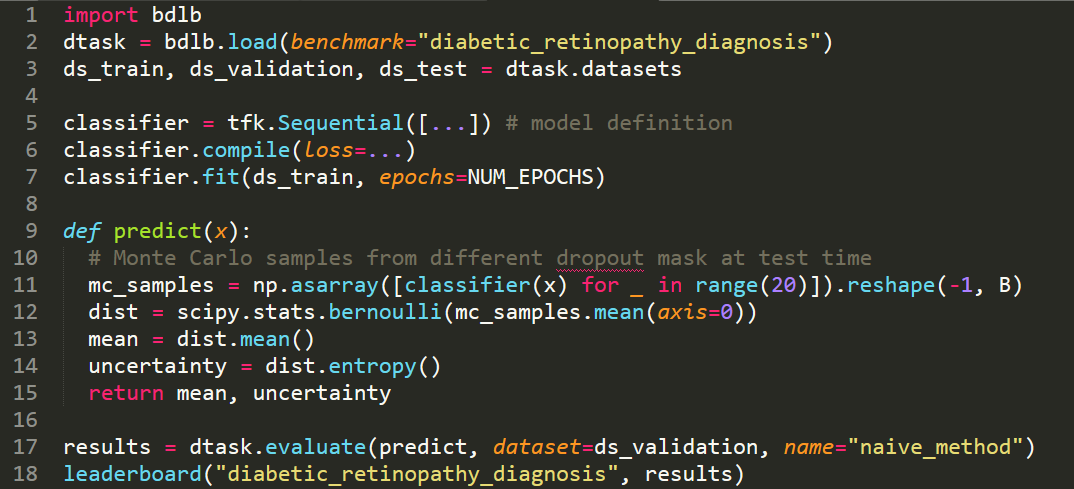
Bayesian Deep Learning Benchmarks
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints. …
Full post...Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Yarin Gal, 14 Jun 2019
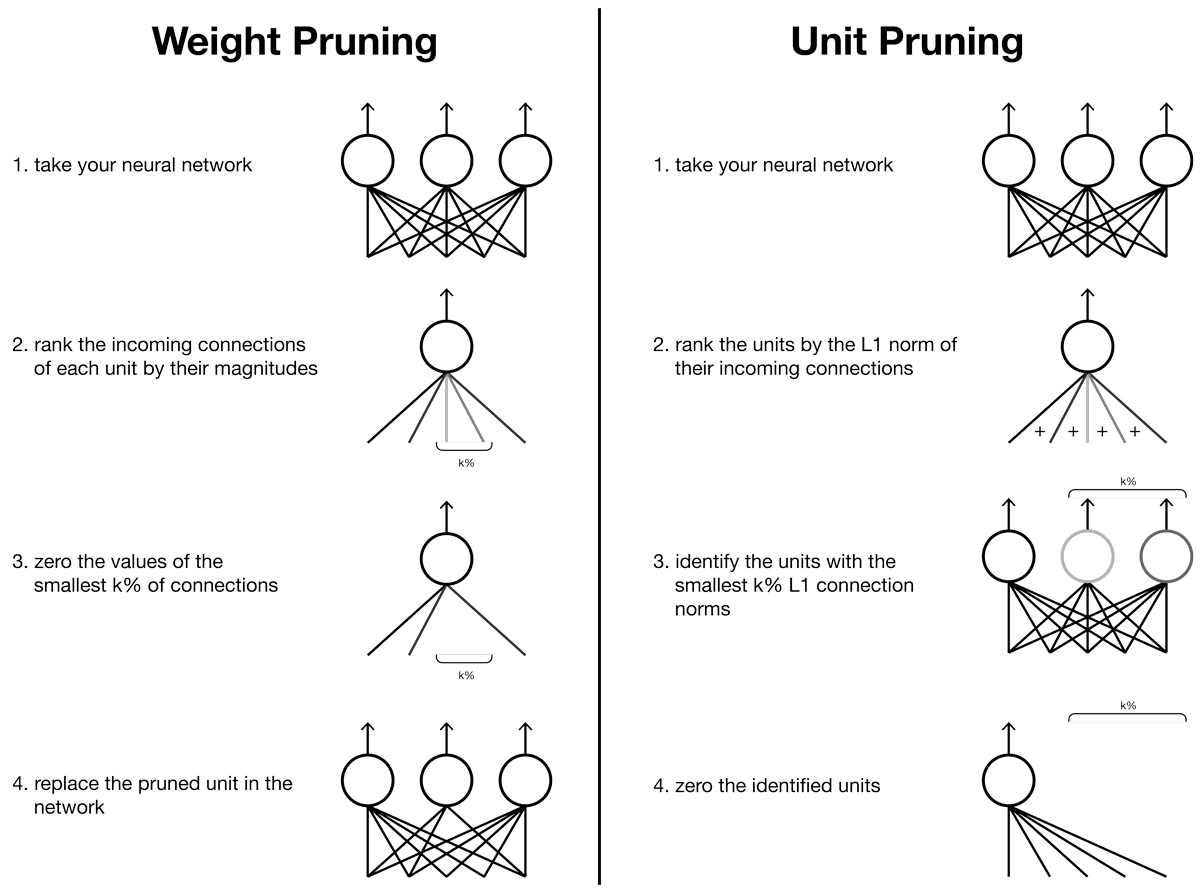
Targeted Dropout
Neural networks can represent functions to solve complex tasks that are difficult — if not impossible — to write instructions for by hand, such as understanding language and recognizing objects. Conveniently, we’ve seen that task performance increases as we use larger networks. However, the increase in computational costs also increases dollars and time required to train and use models. Practitioners are plagued with networks that are too large to store in on-device memory, or too slow for real-world utility. …
Full post...Aidan Gomez, 05 Jun 2019